
Large Language Models have evolved remarkably from pattern-matching systems to sophisticated reasoning engines capable of multi-step problem-solving. This transformation represents a significant shift in AI's ability to process information, connect concepts, and generate solutions to complex problems. The underlying mechanisms enabling these capabilities—from transformer architectures to attention mechanisms—now form the foundation of today's most powerful models.
This article examines the progression of reasoning capabilities in LLMs, from the distinction between System 1 (intuitive) and System 2 (deliberate) reasoning to the emergence of specialized architectures optimized for step-by-step problem-solving. We explore how models like OpenAI's o1, DeepSeek-R1, and Gemini 2.5 Pro are pushing boundaries with their ability to decompose problems, attempt multiple solution approaches, and even correct their own mistakes.
Understanding these advancements provides critical insights for model selection, prompt engineering, and benchmark evaluation for teams building AI products. The techniques covered here—particularly chain-of-thought prompting and its variations—offer practical approaches to enhancing reasoning capabilities in production systems while acknowledging important tradeoffs in token usage, hallucination risks, and computational costs.
Key Topics:
- 1Fundamentals of reasoning architecture and cognitive approaches
- 2Evolution of benchmarks: MMLU-Pro, GPQA, and Diamond challenges
- 3Chain-of-thought techniques and implementation considerations
- 4Mathematical reasoning capabilities across frontier models
- 5Advanced reasoning breakthroughs from 2023-2025
Fundamentals of LLM reasoning: From pattern matching to multi-step problem solving
Large Language Models (LLMs) have evolved from simple pattern-matching systems to sophisticated reasoning engines capable of solving complex problems. This evolution represents a fundamental shift in how artificial intelligence processes information and generates solutions. Let's explore the architectural foundations and cognitive approaches that enable these advanced reasoning capabilities.
The architecture behind reasoning
The transformer architecture serves as the foundation for modern LLM reasoning capabilities. Its attention mechanisms allow models to focus on relevant parts of input data while maintaining awareness of broader context. This architectural design enables LLMs to connect disparate pieces of information when tackling multi-step problems.
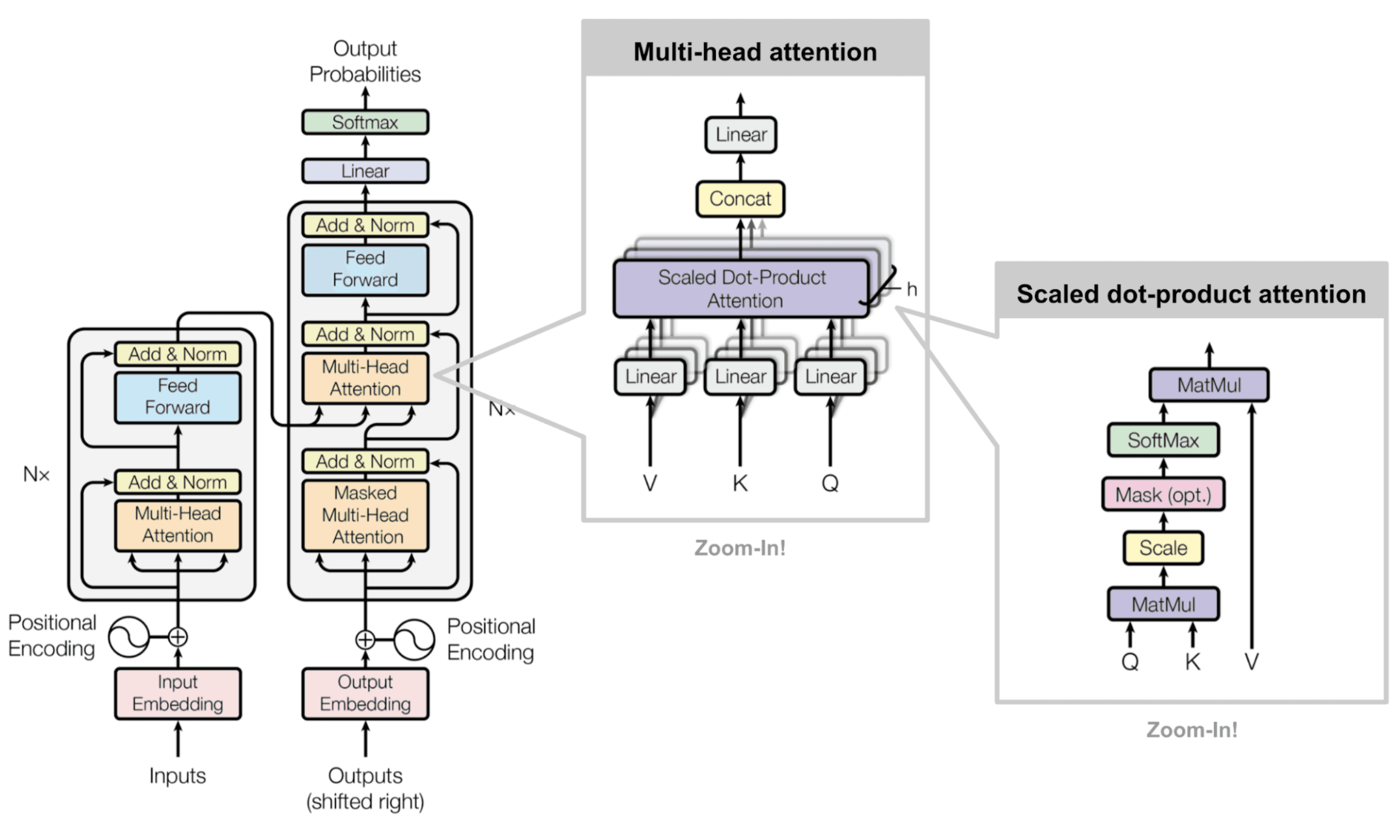
A basic transformer architecture with the attention mechanism. | Source: Attention is all you need
When processing complex questions, LLMs distribute attention across input tokens, creating rich representations that support higher-level reasoning. The context window—the amount of text an LLM can process at once—directly impacts reasoning depth, as longer contexts allow for more comprehensive analysis.
System 1 vs. System 2 reasoning
LLMs exhibit two distinct modes of reasoning that parallel human cognitive processes:

Timeline of reasoning LLMs. | Source: From System 1 to System 2: A Survey of Reasoning Large Language Models
Early LLMs predominantly relied on System 1 reasoning, producing responses based on statistical patterns in training data. Modern models can engage in System 2 reasoning through techniques like chain-of-thought prompting, which encourages explicit reasoning steps.
Balancing memorization and reasoning
LLMs constantly balance memorization and genuine reasoning when solving problems. Simple, frequently encountered problems may be solved through direct recall of similar examples from training data. More complex or novel problems require true reasoning capabilities.
The line between memorization and reasoning remains blurry. Even when an LLM appears to reason through a problem, it may be recombining memorized reasoning patterns rather than performing true logical inference.
The emergence of multi-step problem solving
Recent advancements have dramatically improved LLMs’ ability to tackle problems requiring multiple reasoning steps. Chain-of-thought prompting has proven particularly effective, encouraging models to generate intermediate reasoning steps before arriving at final answers.
Models like OpenAI’s o1 significantly improve complex reasoning by "thinking before answering." These models generate extensive reasoning chains, attempt multiple solution approaches, and even identify and correct their own mistakes.

o1’s performance improvements over train-time and test-time compute. | Source: Learning to reason with LLMs
Today's most advanced LLMs can solve problems that require decomposition into simpler steps, applying appropriate reasoning strategies at each stage. This represents a significant leap toward human-like problem-solving capabilities.
These fundamental architectural and cognitive approaches have laid the groundwork for increasingly sophisticated reasoning capabilities in modern LLMs, setting the stage for more advanced benchmarks to measure their performance.
Evolution of reasoning benchmarks: MMLU-Pro, GPQA, and Diamond
The landscape of reasoning benchmarks has evolved significantly, moving from simple knowledge recall to complex multi-step reasoning assessment. This shift is evident in newer benchmarks like MMLU-Pro, GPQA, and Diamond that push the boundaries of AI capabilities. As we examine these benchmarks, we'll see how they've been specifically designed to test genuine reasoning rather than mere pattern matching.

MMLU-Pro: Enhancing a classic benchmark
MMLU-Pro refines the original MMLU dataset with several key improvements:
- It offers ten choices per question instead of four, requiring more nuanced reasoning
- Expert reviewers have thoroughly vetted the content
- Reduced noise and improved quality throughout the dataset
These changes make MMLU-Pro a more challenging and reliable measure of language model reasoning abilities.
GPQA: Graduate-level reasoning challenges
The General Purpose Question Answering (GPQA) benchmark represents a significant step forward in reasoning assessment. Created by domain experts in biology, physics, and chemistry, GPQA consists of 448 multiple-choice questions specifically designed to be difficult. The benchmark employs a "Google-proof" methodology, meaning answers can't be easily retrieved through simple web searches.
GPQA Performance Comparison:
This significant gap highlights GPQA's ability to measure genuine expert reasoning rather than simple information retrieval.
Diamond: pushing reasoning to new heights
The Diamond tier of GPQA represents the most challenging subset of questions, specifically crafted to test advanced reasoning capacities. These questions require sophisticated problem-solving approaches, including multi-step deduction and cross-domain knowledge application.
Benchmark evolution trends
The progression from earlier benchmarks to these newer, more demanding evaluations reflects a fundamental shift in how we assess AI reasoning. While early benchmarks focused primarily on factual recall, today's standards increasingly measure an AI system's ability to perform complex logical operations, mathematical reasoning, and analytical tasks across multiple steps.
This evolution has proven valuable for tracking progress in language models. Recent advancements through early 2025 demonstrate significant improvements in mathematical reasoning and step-by-step problem solving, particularly visible in performances on challenging tests like AIME 2025.
As reasoning benchmarks continue to evolve, they increasingly focus on assessing genuine understanding rather than pattern matching, pushing AI research toward more sophisticated reasoning capabilities.
With these advanced benchmarks establishing new standards for evaluation, we now turn to the specific techniques that enable models to tackle these challenging reasoning problems effectively.
Chain-of-thought and step-by-step reasoning techniques
Chain-of-thought (CoT) prompting significantly enhances the reasoning capabilities of large language models by asking them to generate step-by-step explanations before producing final answers. This technique has shown impressive performance improvements, particularly on mathematical reasoning tasks, with gains of 28-62% on the GSM8K benchmark.
CoT Variations and Their Applications:
Performance gains of LLMs using standard prompting vs CoT:
The effectiveness of CoT varies with model scale – larger models benefit more from this approach as they can better articulate intermediate reasoning steps. While simple to implement, CoT can be extended through several variations that offer different advantages.
Implementation Tradeoffs:
- 1
Token Usage
Increases 3-5x due to verbose reasoning process - 2
Hallucination Risk
Studies show a 23% error introduction rate in some cases - 3
Computation Requirements
Additional processing impacts inference time and costs
When deciding whether to deploy CoT in production, teams should carefully evaluate the specific task requirements. Simple classification or sentiment analysis may not benefit enough to justify the increased resources, while complex mathematical reasoning, logical problem-solving, and multi-step tasks often show substantial improvements that outweigh the costs.
A single-sentence test is often sufficient to determine if CoT will be beneficial: if a human would need to work through multiple steps to solve a problem, CoT likely will improve model performance.
These step-by-step reasoning techniques have been particularly impactful in enabling models to tackle complex mathematical problems, which we'll explore in the next section.
Mathematics and logical reasoning capabilities in modern models
Building on the chain-of-thought techniques we've discussed, modern LLMs have made remarkable progress in mathematical reasoning – an area that has traditionally been challenging for AI systems. Let's examine how today's leading models perform across various mathematical benchmarks and reasoning tasks.
Comparative analysis of mathematical reasoning benchmarks
Recent benchmarks reveal significant advancements in mathematical reasoning capabilities across frontier models. Gemini 2.5 Pro, GPT-4o, and DeepSeek-V3 have demonstrated exceptional performance on AIME 2025 benchmark tasks, with some models now exceeding human expert performance on quantifiable reasoning problems. The most advanced models can place in the top 500 students in qualifying rounds for the USA Math Olympiad, showing remarkable progress in handling complex mathematical concepts.
LLM Performance on Advanced Reasoning Benchmarks (Late 2024 - April 15, 2025)

DeepSeek-R1’s architecture. | Source: An Analysis of DeepSeek's R1-Zero and R1
DeepSeek-R1’s architecture offers particular advantages for step-by-step problem-solving. Its specialized design enables more structured approaches to mathematical reasoning, allowing for clearer derivation of solutions through sequential logical steps.
Assessment methodologies for evaluating reasoning
Evaluation of logical reasoning in LLMs follows two primary approaches:
- 1
Conclusion-based methods
Focus primarily on the final answer. - 2
Rationale-based approaches
Evaluate the quality and coherence of the reasoning process itself.
Verification systems play a crucial role in mathematical reasoning assessment. Models equipped with self-verification capabilities can identify errors in their reasoning chains and correct them before providing final answers. This dramatically improves accuracy, especially for non-linear problems requiring multiple logical steps.
Chain-of-thought and specialized techniques
Chain-of-thought prompting has become essential for unlocking mathematical reasoning in modern models. This technique encourages models to show their work through explicit step-by-step reasoning before arriving at conclusions.
Key Advancements in Mathematical Reasoning:
- 1
Self-verification
Models critique their own outputs and revise answers - 2
Intermediate calculation verification
Checks each step for accuracy - 3
Code execution skills
Generate, execute, and verify code for precise calculations - 4
Logical deductions
Apply formal rules of inference to solve problems
These approaches have substantially improved performance on challenging mathematical benchmarks.
Recent breakthroughs in code execution skills have significantly bolstered math reasoning capabilities. Models that can generate, execute, and verify code show superior performance on datasets requiring precise numerical calculations and logical deductions.
Reasoning advancements through 2025
The landscape of LLM-based reasoning has evolved rapidly through early 2025. New benchmarks like MMLU-Pro and GPQA Diamond have replaced earlier standards, setting increasingly challenging bars for model performance.
Step-by-step problem solving has become a distinguishing feature of advanced models. This approach allows complex problems to be broken down into manageable components, improving both accuracy and explainability.
Models can now handle increasingly abstract concepts, moving beyond pattern matching to demonstrate genuine mathematical insight. This capability enables them to tackle novel problems that require creative applications of mathematical principles rather than memorized solutions.
These mathematical reasoning capabilities represent just one aspect of the tremendous progress made in LLM reasoning over the past few years. Next, we'll explore the broader landscape of reasoning breakthroughs across different models and approaches.
Advanced reasoning breakthroughs (2023-2025)
The landscape of advanced reasoning in Large Language Models (LLMs) has seen remarkable evolution between 2023 and 2025. New benchmarks like MMLU-Pro and GPQA Diamond have raised standards beyond traditional tests, creating higher bars for model performance. Let's examine some of the most significant breakthroughs that have pushed reasoning capabilities to new heights.
OpenAI’s o1 reasoning model
OpenAI’s o1 model represents a significant leap in reasoning capabilities. Its approach centers on allowing the model to "think" before responding through extended chains of thought. This enables the model to break down complex problems, try multiple approaches, and even correct its own mistakes.
o1 Performance Metrics:
- 93% accuracy on AIME
- 77.3% on GPQA Diamond
What's particularly noteworthy is how o1's reasoning capabilities improve with additional compute (OpenAI):
"We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute)."
DeepSeek-R1’s optimization techniques
DeepSeek-R1 has implemented innovative techniques focusing on chain-of-thought reasoning. Their approach utilizes reinforcement learning with specialized length rewards to optimize reasoning patterns. This addresses the critical “overthinking” problem that has plagued many LLMs.
Solving the overthinking problem
Many LLMs struggle with generating excessively verbose reasoning paths. Technical solutions now include:
- 1Length penalty mechanisms to discourage unnecessarily long chains
- 2Dynamic compute allocation that adjusts reasoning depth based on problem complexity
- 3Targeted reinforcement learning signals that reward efficient paths to solutions
Architectural innovations
The core architecture driving these reasoning improvements includes:
These architectural advances have enabled models to perform complex reasoning that previously seemed beyond reach of artificial systems.
These breakthroughs in advanced reasoning capabilities have fundamentally transformed the landscape of what’s possible with large language models, setting the stage for even more sophisticated applications in the future.
Conclusion
The evolution of reasoning capabilities in LLMs has fundamentally transformed what's possible in AI applications. From the architectural foundations of transformer models to specialized techniques like chain-of-thought prompting, we've witnessed models progress from simple pattern matching to sophisticated multi-step reasoning that can tackle increasingly complex problems.
Key Developments in LLM Reasoning:
- Transition from pattern matching to multi-step problem solving
- Development of more demanding benchmarks (MMLU-Pro, GPQA, Diamond)
- Emergence of models with impressive reasoning capabilities (o1, o3, DeepSeek-R1, Gemini 2.5 Pro)
- Performance sometimes exceeding human experts on quantifiable reasoning tasks
For product teams, these advancements create opportunities to develop more capable applications while introducing important considerations. When implementing reasoning techniques, evaluate the complexity-cost tradeoff—simpler tasks may not benefit enough from chain-of-thought to justify the 3-5x increase in token usage and potential hallucination risks. For complex reasoning tasks, consider specialized models with self-verification capabilities that can detect and correct errors in their reasoning chains.
As these technologies continue to advance, the distinction between memorization and genuine reasoning will remain a central research focus, pushing the field toward AI systems with increasingly sophisticated problem-solving abilities that can deliver transformative value across domains.