When you send a question to ChatGPT or another AI, your prompt starts a complex series of processes. Knowing this machinery isn't just for learning; it helps you create prompts that get the responses you want. For teams making AI products, knowing how prompts lead to useful outputs can boost your strategy and results.
This guide breaks down the technical journey of a prompt through an LLM, from tokenization to reasoning. We look at the key ways these models understand language, keep track of context, and give clear answers. These ideas will help you use your tokens better, create stronger prompts, and use advanced reasoning skills.
By implementing these insights, you’ll address common challenges in AI product development: improving response quality, reducing computational costs, managing token limitations, and enhancing reasoning capabilities. These techniques directly translate to more reliable AI features and better user experiences.
Key concepts covered:
- 1Understanding tokenization and its impact on costs and efficiency
- 2Embedding processes that transform words into mathematical vectors
- 3Transformer architecture and attention mechanisms
- 4Context window optimization for information retrieval
- 5LLM reasoning patterns and how to elicit better thinking
- 6Advanced prompt engineering techniques for complex tasks
Tokenization: Converting Text Inputs into Model-Readable Units
Before an LLM can begin processing your prompt, it must first break down the text into manageable pieces that the model can understand. This critical first step sets the foundation for all subsequent processing.

Source: Tokenizer
Tokenization is the crucial first step in how large language models process text. It involves breaking down input text into smaller units called tokens that the model can understand and analyze. For the English language, one token typically represents about 0.75 words or roughly four characters.
How tokenization works
Different LLMs use various tokenization methods to divide text into manageable units. Popular approaches include Byte Pair Encoding (BPE), WordPiece, and SentencePiece. These methods break words into meaningful subcomponents. For example, the word "tokenization" might be divided into the tokens "token" and "ization," as each subword contributes to understanding the complete word.

Source: Tokenization in NLP
The effectiveness of an LLM often hinges on its tokenization strategy. Subword tokenization techniques can significantly reduce out-of-vocabulary errors by breaking unknown words into familiar subword components.
Tokens and model costs
Tokens serve as the basic units of measurement for LLM processing costs. Most providers charge based on the number of tokens processed, including both input and output tokens. Understanding token usage is essential for optimizing costs.
Token comparison example:
Impact on prompt engineering
Tokenization directly affects prompt engineering through:
Token budget management
LLMs have context window limits ranging from a few thousand to 128,000 tokens. Effective token usage means prioritizing relevant information and removing redundancy.
Check out the token limit or context limit of all the models released this year til 17 April 2025:
Input optimization
Compression techniques like LLMLingua can reduce token count by identifying and removing low-importance tokens while preserving meaning, helping to fit more information within token limits.
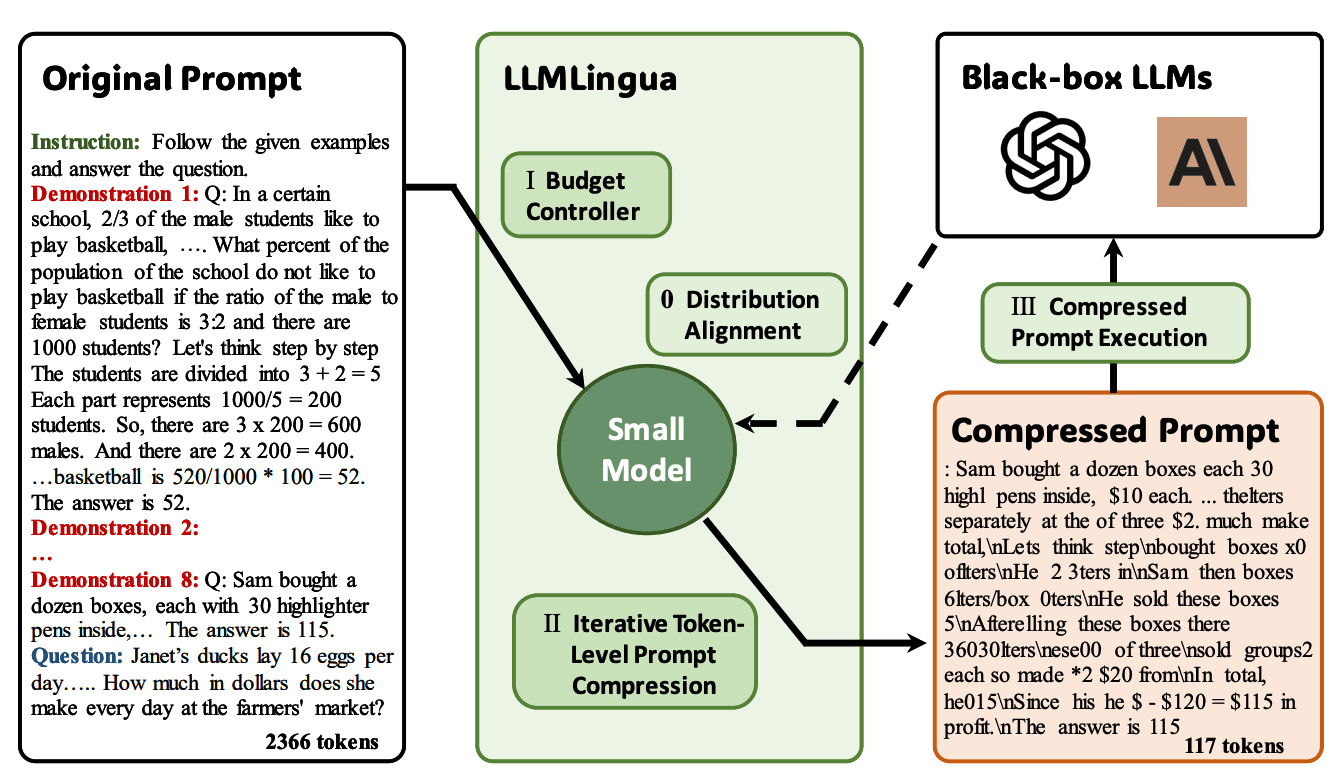
Overview of how LLMLingua works | Source: LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
Language variations
Different languages tokenize differently. Languages with complex morphology may require more tokens to represent the same content than others.
Improving token efficiency

Token efficiency can be enhanced through:
- Structuring information from most to least important
- Using concise language that preserves clarity
- Implementing prompt compression techniques
- Estimating token usage before submission
Understanding tokenization is fundamental for effectively working with LLMs, especially when managing costs and maximizing the information that can be included within context windows. The way your text is tokenized directly influences how much information you can include in a prompt and what it costs to process it.
Embedding Processes: From Tokens to Vector Representations
Once text has been broken into tokens, LLMs need to convert these discrete symbols into a mathematical form they can process. This is where embeddings transform language into a numerical space where meaning can be manipulated.
Understanding token embeddings

Embeddings form the foundation of language modeling in LLMs. When text is processed, it's first divided into tokens—words, subwords, or characters—that the model can understand. These tokens are then converted into numerical vectors called embeddings, which capture semantic relationships between elements of text.
The embedding process maps discrete units of words (tokens) to numerical vectors. For example, the word "tokenization" might be broken down into "token" and "ization" since each subword contributes to understanding the complete word.
From words to mathematical representations
During the prefill phase of LLM inference, input tokens are transformed into vector embeddings—numerical representations that the model can work with. These embeddings capture the semantic essence of each token, complemented by positional encodings that provide information about sequence order.
Each token’s embedding vector is multiplied by weight matrices learned during training to produce query, key, and value vectors through linear projection. This mathematical representation allows the model to process language with computational techniques.
Contextual embeddings
List of Embeddings models in 2025:
Contextual embeddings generate different representations for the same word depending on the surrounding words.
Visualizing embeddings in vector space
Embeddings position words in a high-dimensional space where similar concepts appear closer together. This geometric arrangement allows models to reason about relationships between concepts mathematically rather than symbolically.

2D embeddings visualized using t-SNE | Source: Visualizing the embeddings in 2D
For complex text with rarely used vocabulary or words with prefixes and suffixes, subword representations can break these elements down further. This approach is particularly useful for handling out-of-vocabulary words and morphologically rich languages when standard contextual embedding techniques might not be sufficient.
The power of embeddings lies in their ability to translate the complexity of language into a mathematical framework that machines can process efficiently while preserving meaning. Through this translation from symbols to vectors, LLMs gain the ability to understand relationships between words and concepts in ways that enable sophisticated language processing.
Transformer architecture and attention mechanisms
With tokens converted to embeddings, the model now needs to process these representations to understand the relationships between them. The transformer architecture, particularly its attention mechanisms, is what enables LLMs to capture these complex relationships.
Core components of transformers
The transformer architecture forms the backbone of modern Large Language Models (LLMs). At its heart lies the self-attention mechanism, which analyzes relationships between all tokens simultaneously. This parallel processing capability gives transformers their remarkable power to understand context.
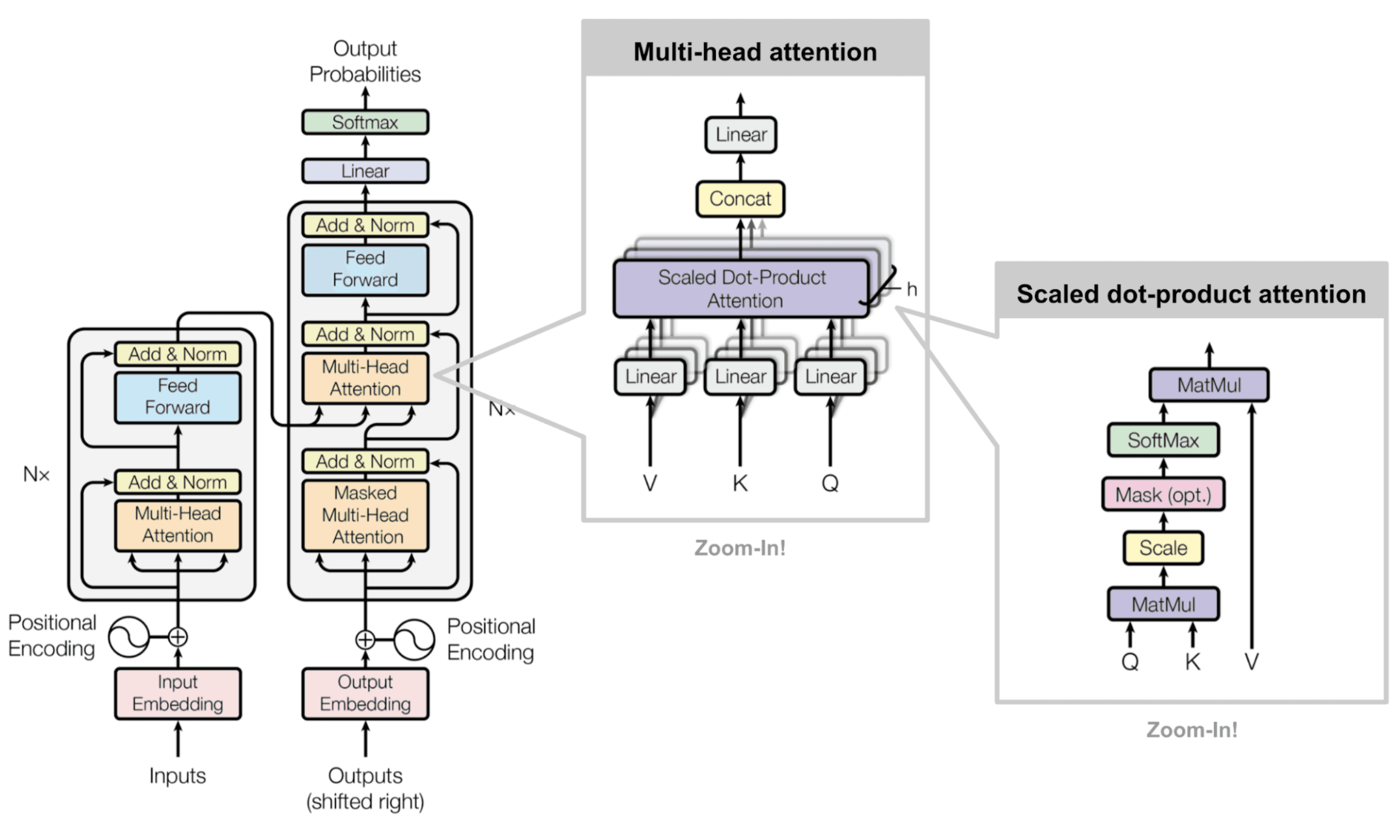
Transformer architecture | Source: Attention Is All You Need
Key transformation steps:
- 1Convert tokens into numerical vectors (embeddings)
- 2Process embeddings through attention mechanisms
- 3Compute three matrices: queries, keys, and values
- 4Apply mathematical operations to determine relationships
The attention mechanism works by computing three matrices from the input: queries, keys, and values. This approach draws inspiration from database operations, where users retrieve data by making queries that match keys to access values.
Self-attention computation
The attention function maps queries and key-value pairs to an output using a compatibility function. For each query, the model calculates attention weights by comparing it with all keys. These weights determine how much focus to place on different parts of the input sequence.
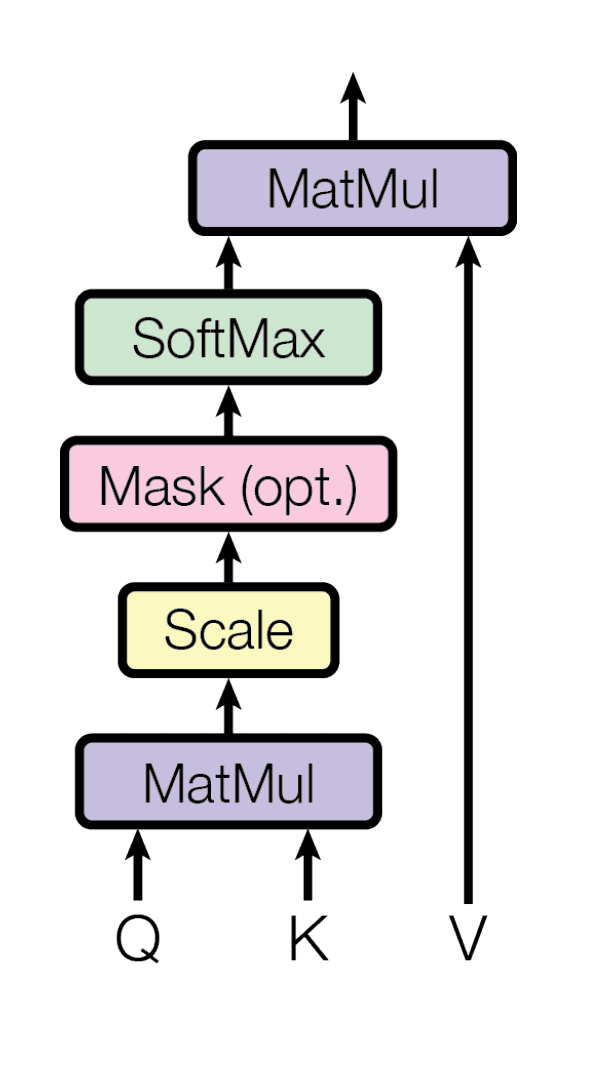
Self-attention diagram | Source: Attention Is All You Need
The famous equation from "Attention is all you need" expresses this mathematically:
Here, Q, K, and V represent the query, key, and value matrices, while dk is the dimension of the key vector. The division by √dk prevents values from becoming too large, stabilizing the training process.
Multi-head attention implementation
Instead of using a single attention function, transformers employ multi-head attention. This approach runs multiple attention operations in parallel with different learned projections of Q, K, and V matrices.

Multi-head attention diagram | Source: Attention Is All You Need
Multi-head attention allows the model to jointly attend to information from different representational subspaces. Each attention head can focus on different aspects of the input - some might track syntactic structure, while others capture semantic relationships or long-range dependencies.
The outputs from these parallel operations are concatenated and linearly projected to produce the final attention output. This enables more comprehensive understanding of the input sequence by capturing various relationships simultaneously.
Optimization techniques
The computational complexity of standard attention grows quadratically with sequence length, creating challenges for processing long prompts. Several techniques address this limitation:
Advanced attention optimization methods:
- 1
Grouped-query attention (GQA)
Shares key and value heads among multiple queries, balancing memory requirements with model quality. Implemented in models like Llama 2 70B. - 2
Multi-query attention (MQA)
Uses a single key-value head across all queries, significantly reducing memory bandwidth and accelerating decoder inference speed. - 3
FlashAttention
Optimizes memory usage by breaking attention computation into smaller chunks and reducing read/write operations to GPU memory.
These optimizations make transformer-based LLMs more efficient while maintaining their powerful contextual understanding capabilities. By orchestrating complex attention patterns, transformers enable LLMs to weigh the importance of different parts of your prompt and establish meaningful connections between concepts.
Context Windows and Information Retrieval
As we better understand how LLMs process information internally, we must consider the practical limitations of how much context they can handle at once. The context window represents this crucial boundary and influences how information should be structured for optimal processing.
Context windows in large language models (LLMs) define how much information the model can process at once. While longer context windows offer more comprehensive understanding, they come with several challenges.
Signal dilution in large context windows
As context windows grow, important information can get "lost in the middle." Studies show that LLMs retrieve information most effectively from the beginning and end of prompts, with significantly degraded performance for content placed in the middle sections. This signal dilution varies across model sizes, with larger models generally maintaining better context retention.
Window chunking strategies
To process documents exceeding token limits, effective chunking strategies are essential:
Recommended chunking approaches:
- Prioritize relevant information directly related to the task
- Remove redundant content
- Structure information from most to least important
- Include specific examples or reference cases
For estimating maximum document size, use this formula:
Where α is a reduction factor (typically 0.5) for reliable performance.
Context retention measurement
Context retention across window sizes can be assessed through:
- 1Recall metrics testing retrieval of specific information at varying positions
- 2Comparison tests across different context lengths
- 3Evaluation of coherence maintenance throughout long contexts
When documents exceed context limits, alternative approaches like Retrieval Augmented Generation (RAG) offer better solutions by connecting LLMs to external knowledge bases.
The measurement of context effectiveness involves both quantitative metrics (accuracy, recall) and qualitative assessment of response coherence when drawing from multiple sections of lengthy inputs. Understanding these context window dynamics is essential for designing prompts that position critical information where the model is most likely to effectively process it.
LLM reasoning patterns and mechanisms
Now that we understand how LLMs process information, we can explore how they actually reason with that information to generate meaningful responses. The reasoning capabilities of LLMs represent one of their most powerful and nuanced features.
Large language models (LLMs) possess sophisticated reasoning abilities that can be elicited through specific prompting techniques. These abilities weren't immediately apparent in early models but have emerged as a fundamental capability when properly accessed.
Chain-of-thought reasoning
Chain-of-thought (CoT) prompting was one of the first techniques to demonstrate LLMs' reasoning capabilities. This simple prompt-based approach asks the model to explain its thinking before providing a final answer. When an LLM generates a step-by-step rationale, its reasoning capabilities improve significantly while making outputs more interpretable to humans.

Standard prompting vs Chain of thought prompting | Source: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Applications of chain-of-thought:
- Evaluation models provide scoring rationales before final evaluations
- Supervised finetuning teaches smaller models to write better reasoning chains
- Self-reflection enables models to critique and revise their own outputs
Zero-shot vs. few-shot learning
LLMs can approach reasoning tasks through different learning frameworks:
Research shows that for complex reasoning tasks, few-shot learning with chain-of-thought examples typically outperforms zero-shot approaches, though performance varies across domains.
Pattern recognition foundations
At their core, LLM reasoning abilities emerge from pattern recognition capabilities learned during training. These models identify and apply patterns in data to solve novel problems. Recent research indicates that LLMs developed inherent reasoning abilities during pre-training, but these abilities require specific elicitation techniques.
Limitations and mitigations
Despite advances, LLM reasoning still exhibits limitations. Models can accumulate errors in multi-step reasoning processes and may struggle with certain types of logical problems.
Technical mitigation strategies:
- 1Step-level verification during reasoning
- 2Teaching models to incorporate verification into their reasoning process
- 3Advanced training strategies like OpenAI's o1 reasoning model
As research progresses, new training algorithms that teach LLMs to incorporate verification into their reasoning process show promising results for more robust cognitive capabilities. Understanding these reasoning mechanisms allows us to design prompts that effectively tap into these capabilities while accounting for their limitations.
Advanced Prompt Engineering for Enhanced Reasoning
With a solid understanding of how LLMs process and reason with information, we can now explore advanced techniques to enhance their reasoning capabilities through strategic prompt design.
Chain-of-thought prompting techniques
Chain-of-thought (CoT) prompting has transformed how we leverage LLMs' reasoning capabilities. By instructing models to provide step-by-step explanations before generating answers, we significantly enhance their problem-solving abilities. This approach mimics human multi-step reasoning processes, articulating intermediate steps in concise sentences that lead to the final answer.
While CoT shows substantial improvements in math problem-solving tasks, its effectiveness varies across domains. For example, in medical question-answering tasks, researchers found minimal improvement over few-shot prompting strategies.
Self-consistency and ensemble approaches
Self-consistency prompting expands beyond CoT by sampling multiple reasoning paths instead of following only the greedy solution. This technique acknowledges that complex problems often have various valid reasoning routes to reach the correct solution.
Ensemble refinement learning takes a two-step approach:
- 1Use chain-of-thought prompts to randomly produce multiple explanations
- 2Refine the model based on aggregated answers to produce more nuanced explanations
Meta-prompting for system-level control

Meta-prompting extends traditional prompt engineering by creating prompts that instruct AI systems how to respond to future prompts. Unlike conventional prompting which focuses on direct instructions, meta-prompting establishes overarching frameworks guiding how the AI interprets subsequent inputs.
Areas of improvement with meta-prompting:
- Accuracy
- Consistency
- Alignment with human intent
- Complex reasoning tasks
- Education scenarios
- Research contexts
- Enterprise environments
Structured output for consistent information extraction
Formatting prompts with clear structures significantly improves reasoning quality. Using templates like:
This approach helps models organize their thinking process.
For extracting consistent information, instructing LLMs to generate structured outputs like JSON provides machine-readable responses. This improves reliability, reduces the need for validation or retries, and enables programmatic detection of refusals.
Problem decomposition strategies
Breaking complex reasoning tasks into smaller, manageable components has proven effective. This can be implemented through prompt chaining, where outputs from one prompt serve as inputs for subsequent prompts.
Example decomposition process:
- 1Summarize background information
- 2Generate potential approaches
- 3Create detailed solutions based on approaches
By mastering these advanced prompt engineering techniques, we can significantly enhance LLMs' reasoning capabilities and produce more reliable, accurate, and useful outputs for complex tasks.
Conclusion
The journey from prompt to response in LLMs involves multiple sophisticated processes working in concert. Understanding these mechanisms—tokenization, embedding, attention, and reasoning patterns—provides essential insights for anyone building AI-powered products.
The technical knowledge presented here directly translates to practical implementation advantages. Optimizing token usage reduces costs while maximizing context window utilization. Structuring prompts with reasoning patterns in mind leads to more reliable, accurate outputs. Advanced techniques like chain-of-thought prompting and meta-prompting enable more complex reasoning tasks previously considered beyond AI capabilities.
Key takeaways for teams:
- Product teams: Use this knowledge to inform feature design decisions and structure user interactions
- Engineers: Implement robust prompt templates accounting for token efficiency and reasoning patterns
- Leadership: Make strategic decisions about AI competitive advantages while realistically assessing limitations
As LLM technology continues evolving, the teams that understand what happens beneath the surface will be best positioned to build truly transformative AI products.