
OpenAI’s o3 and DeepSeek’s already-released DeepSeek R1 are set to redefine AI reasoning. o3 leverages innovative test-time search to achieve high-performance reasoning, while DeepSeek R1 has captured attention for its cost‐efficient design, transparent “aha moment,” and ability to tackle math, coding, and logic challenges at a fraction of traditional costs.
In this article, we explore what’s happening inside these next-generation reasoning models by examining:
- 1How they work under the hood
- 2Their performance on key reasoning benchmarks
- 3Practical applications and use cases for businesses
- 4Their implications for the future trajectory of AI
Note: While details on OpenAI’s o3 are still emerging, I’ll provide as much insight as possible into its design and capabilities.
What are reasoning models?
Reasoning models in AI are designed to emulate human-like logical thinking through a step-by-step process rather than relying solely on pattern matching. This approach allows the model to generate intermediate reasoning steps, resulting in more transparent and interpretable solutions.
The human parallel:
- Neurological insight: In the human brain, the prefrontal cortex manages working memory and logical inference.
- Psychological aspect: Human reasoning blends intuitive leaps with systematic analysis, enabling us to draw conclusions from information.
Contrast with traditional LLMs: Older models, such as those following the GPT-3 style, primarily depend on pattern recognition. This can lead to issues like hallucinations, which produce plausible but incorrect outputs. In contrast, next-generation models like OpenAI's o3 and DeepSeek's DeepSeek R1 integrate advanced techniques to handle logic, math, and complex tasks with greater reliability.
Why o3 and DeepSeek R1 stand out:
- 1
Step-by-step reasoning
They generate intermediate steps before reaching a final answer, mirroring human problem-solving. - 2
Enhanced transparency
Their approach offers clear, interpretable reasoning, addressing some limitations of older, pattern-based models.
This innovative reasoning process sets a new benchmark in AI development, paving the way for more robust and reliable intelligent systems.
Key techniques in modern reasoning models
Both DeepSeek R1 and OpenAI o3 utilize specialized techniques to enhance their reasoning capabilities. Below are three core mechanisms:
CoT is a prompting technique where the model is encouraged to generate a sequence of intermediate reasoning steps before reaching the final answer. Instead of jumping straight to an output, the model “thinks out loud” by:
- Breaking down tasks: When faced with a complex query, such as a multi-step math problem, the model outputs a series of intermediate steps. Instead of simply providing the solution to an equation, it might outline the calculation process step by step.
- Enhancing transparency: Showing these intermediate steps makes the process more transparent and interpretable, making it easier to identify where a mistake might occur.
- Training on intermediate outputs: During training, models are exposed to examples where the correct answer is accompanied by detailed reasoning, allowing them to learn how to generate coherent and logical thought sequences.
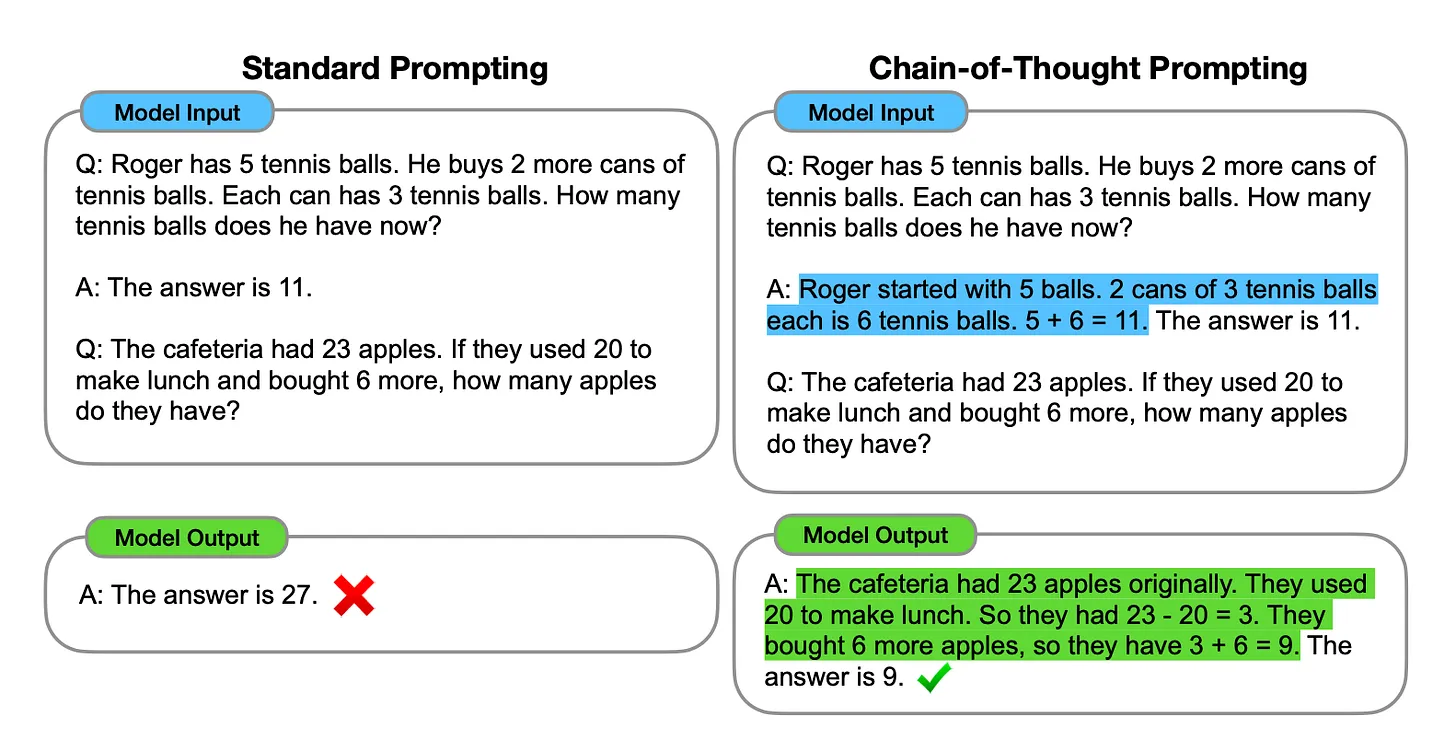
A comparison between standard prompting and chain-of-thought prompting | Source: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Why it matters: CoT is particularly effective for tasks requiring methodical, sequential logic—such as puzzle-solving and detailed analytical reasoning.
Test-time Search is an inference strategy that OpenAI o3 uses to boost reasoning accuracy by dynamically exploring multiple candidate CoTs. Instead of immediately outputting a single answer, o3 generates several distinct reasoning paths and then selects the best one.
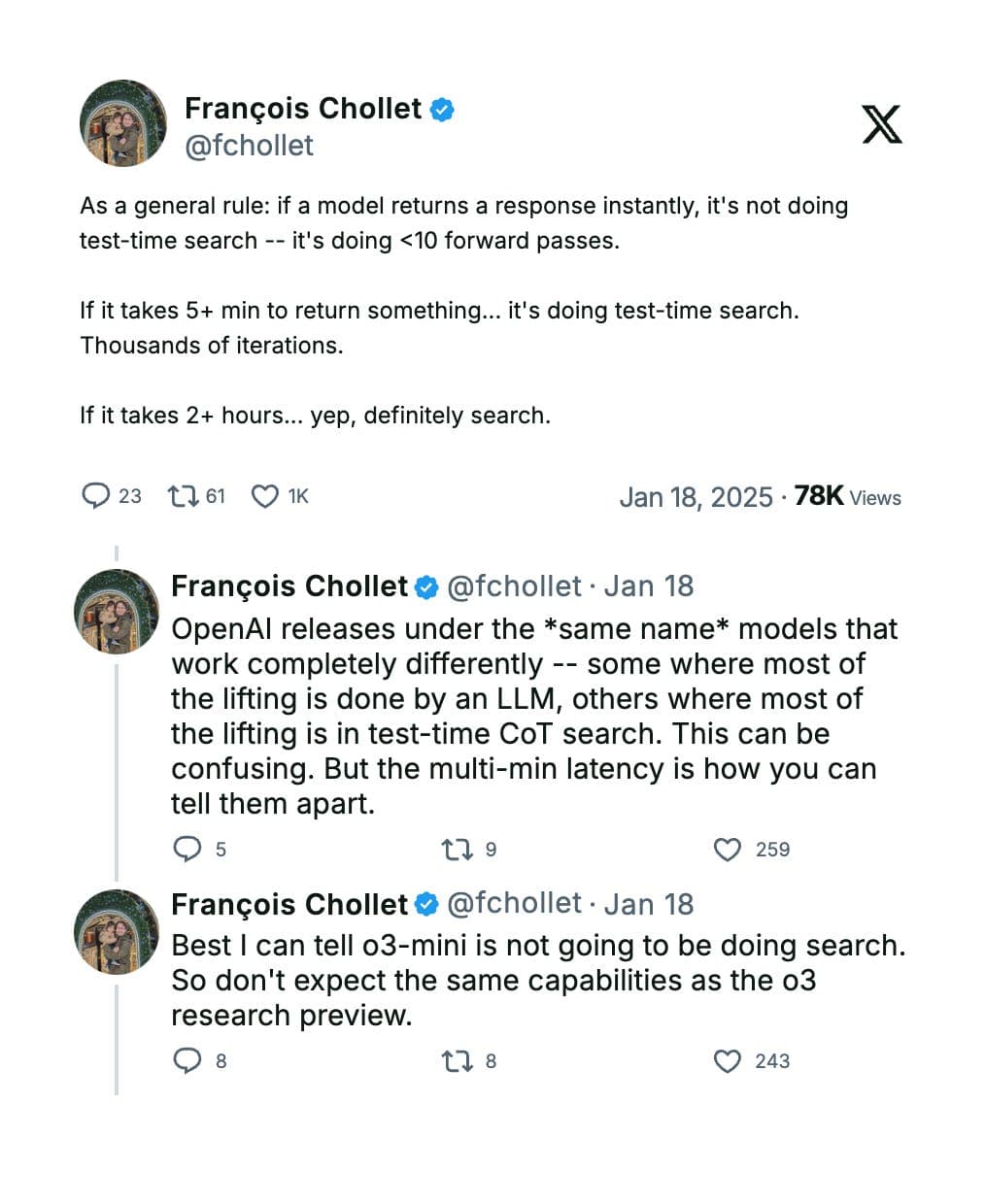
Source: François Chollet on X
Here’s how it works
Multiple candidate generation:
- When faced with a query, o3 generates a diverse set of candidate CoTs, each representing a distinct “program” or step-by-step reasoning pathway to solve the task.
- This process mimics a human iterating over different drafts of a solution before settling on the best one.
Natural language program search:
- Instead of relying on a single, linear CoT, o3 searches over a vast space of natural language “programs”—each a candidate reasoning sequence.
- This search is guided by the model’s deep learning prior, which helps it assess the plausibility of each reasoning path.
Dynamic evaluation and selection:
- Advanced search techniques, similar in spirit to beam search or even Monte Carlo Tree Search, are employed to evaluate candidate CoTs based on internal consistency, logical coherence, and task alignment.
- A verifier or evaluator model assesses these candidates, selecting the one with the highest score as the final output. This selection process helps filter out errors or hallucinations and ensures robust decision-making.
Why it matters: By exploring multiple reasoning paths, the model reduces errors and hallucinations for enhanced accuracy while dynamically adapting to novel challenges, ensuring reliable performance on complex tasks.
MoE is an architectural approach that differs fundamentally from the methods described above. Instead of a single monolithic network, MoE divides the model into multiple specialized sub-networks—each known as an expert. Here’s a detailed breakdown:
- Specialization of experts: Each expert is trained to handle specific tasks or reasoning patterns. For instance, one expert might specialize in mathematical reasoning while another excels at language understanding.
- Efficiency and scalability: Because only a subset of experts is activated for any particular query, MoE models can be extremely efficient. They offer a high capacity while keeping computational costs in check.
- Dynamic routing via a gating mechanism: A small gating network determines which experts are most relevant for a given input. The gating function computes a relevance score for each expert, and only the most pertinent ones are activated. This process can be mathematically described as follows:
Where,
x, is the input, fi(x), is the output from the ith expert,Softmax(Wgx)i, is the gating weight that determines the contribution of each expert.
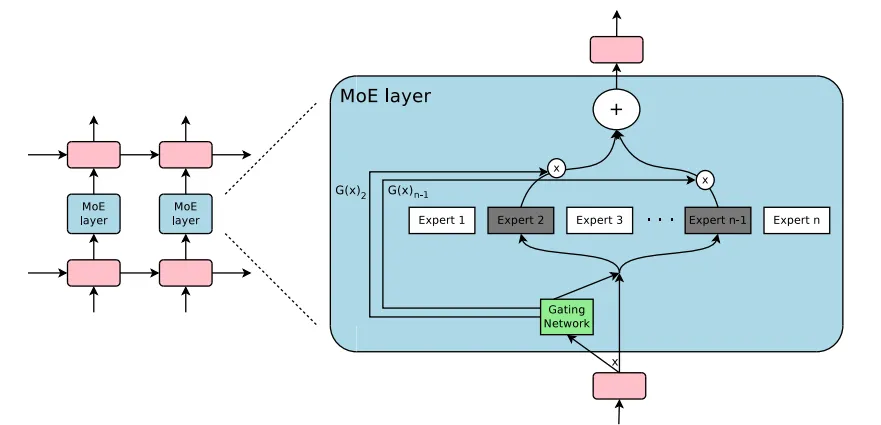
The Architecture of MoE | Source: Mixture of Experts Explained
Why it matters: DeepSeek R1 employs an MoE architecture, which allows it to select the optimal “expert” sub-model for each task. This results in high efficiency and versatility.
Training Techniques
In this section, I will break down the training techniques of both models.
DeepSeek R1: Multi-stage reinforcement learning with GRPO
At its core, DeepSeek R1 employs a systematic 4-phase approach combining supervised learning and reinforcement learning:
Phase 1: Cold start
Initialization & Formatting Compliance
- Base model initialization: Begins with DeepSeek-V3-Base, a 671B parameter Mixture-of-Experts (MoE) model.
- Supervised fine-tuning (SFT): Applies SFT on a curated dataset of ~1,000 high-quality samples generated from validated reasoning outputs.
Phase 2: Reasoning-oriented reinforcement learning
Group Relative Policy Optimization (GRPO)
- RL approach: Utilizes a rule-based RL variant—GRPO—which samples multiple responses per input.
- Reward criteria:
• Accuracy: Assessed via objective metrics such as code test cases and math correctness.
• Formatting: Enforces adherence to structured output templates.
• Language Consistency: Imposes penalties for code-switching between languages. - Focus: Targets coding, math, and logical reasoning tasks with clear, quantifiable correctness standards.
Phase 3: Rejection sampling + SFT
Data Expansion & Filtering
- Sample generation: Generates 600K reasoning samples using the Phase 2 model.
- Filtering process: Samples are screened for correctness (via DeepSeek-V3 validation) and readability (ensuring no mixed languages or overly long paragraphs).
- Data augmentation: Combine these samples with 200K general-domain SFT examples (covering writing, translation, etc.).
- Fine-tuning: Conducts 2 epochs of SFT to broaden the model’s capabilities beyond reasoning tasks.
Phase 4: Diverse reinforcement learning
Final RL Optimization
- Enhanced reward systems: Integrates rule-based rewards for structured tasks (e.g., math and code) along with LLM-based reward models tuned to human preferences (helpfulness/harmlessness).
- Generalization: Aims to boost performance across 100+ task categories, ensuring versatility and robustness.
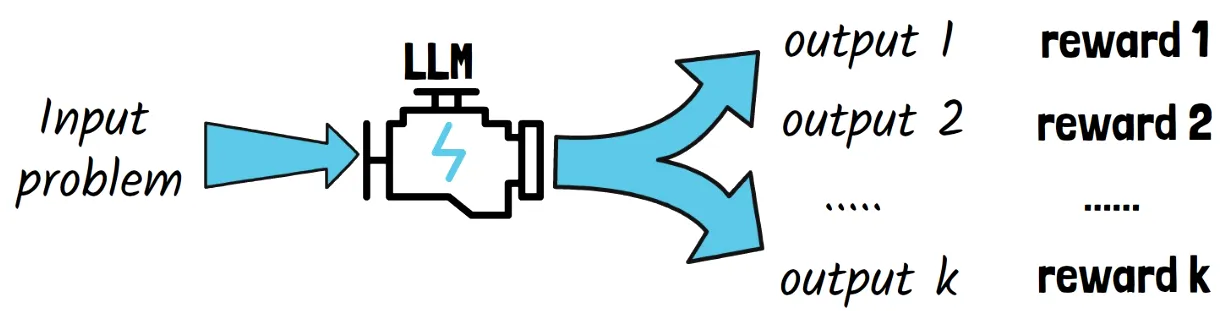
Diagram of how various input is rewarded | Source: DeepSeek-DeepSeek R1 Paper Explained – A New RL LLMs Era in AI?
OpenAI O3’s training Pipeline: deliberative alignment & reinforcement learning
I should note that most of the information about OpenAI o3 and even OpenAI o1 comes from closely following the people who made it. I did thorough research on the makers of OpenAI o1 and OpenAI o3 through their tweets, interviews, and podcasts to write this section.
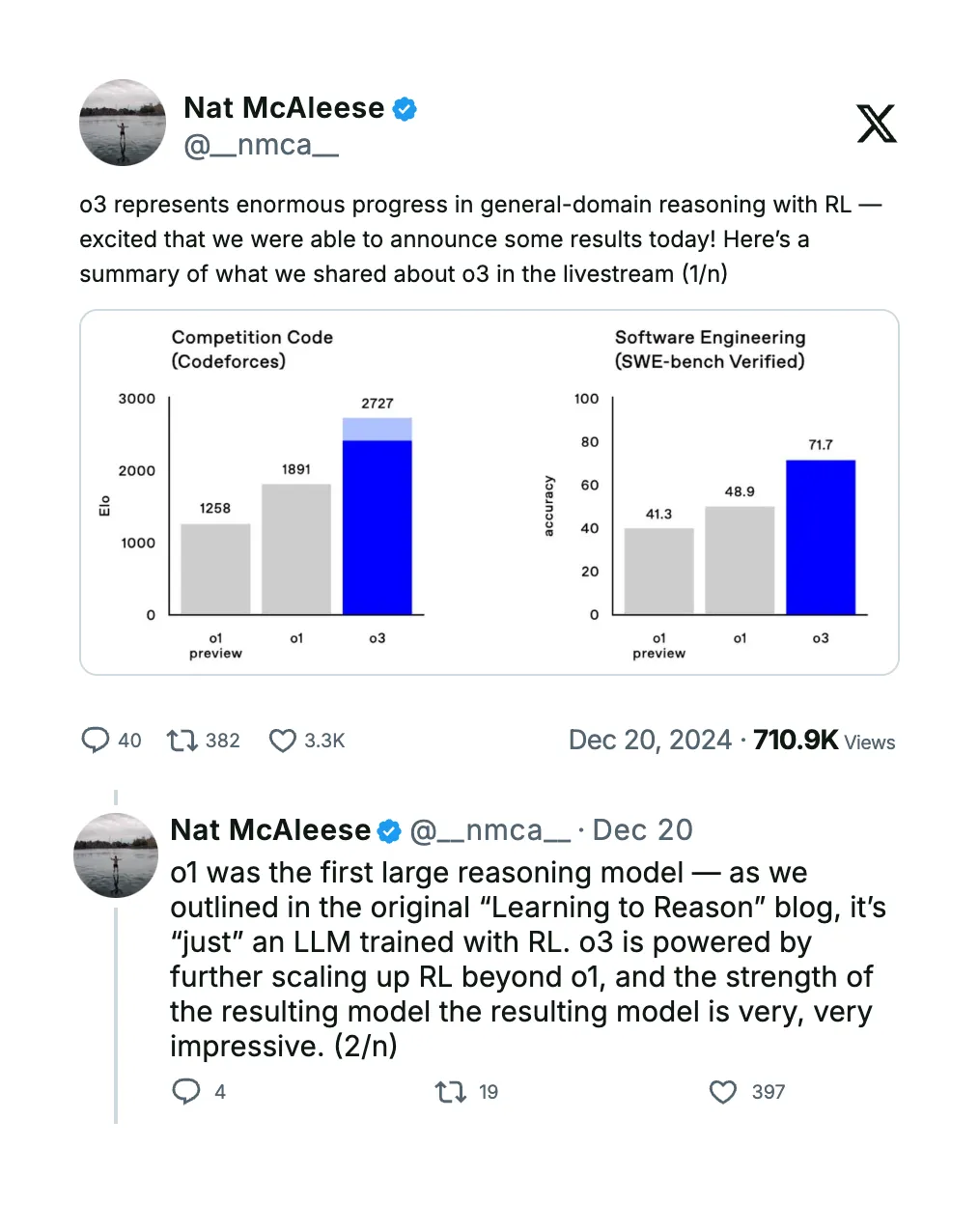
Source: Nat McAleese on X
OpenAI o3 builds on the earlier OpenAI o1 model by scaling up reinforcement learning and integrating a novel safety-focused process called deliberative alignment while also incorporating a test-time search during inference to refine its outputs further.
Source: Jason Wei on X
Here is the breakdown of the training process:
Phase 1: base model & pre-training
Training using prompt dataset
- OpenAI o3 begins with a dense transformer pre-trained on vast amounts of text and fine-tuned on datasets containing prompt, CoT, output tuples, laying a solid foundation in language understanding and reasoning.
Phase 2: Scaling up reinforcement learning
Leveraging RL to develop reasoning
- Extended CoT generation: The model generates hundreds or thousands of candidate reasoning paths, breaking down complex tasks into detailed, step-by-step processes.
- Candidate verification & reinforcement signal: An evaluator model reviews these candidates for calculation errors and logical mistakes, and only the correct paths are used as targets for further reinforcement learning.
- Key innovation: By training on verified reasoning sequences, o3 shifts from merely predicting the next word to reliably forecasting a series of tokens, leading to the correct answer.
Phase 3: Model safety and human feedback
Deliberative alignment for safety & coherence
- Self-review mechanism: The model “thinks over” its CoT before finalizing an answer, checking for errors or unsafe content.
- Human feedback integration: Fine-tuning with examples of safe versus unsafe prompts aligns O3’s internal reasoning with human values, ensuring its outputs are both accurate and safe.
Phase 4: Inference
Test-time search
- Multiple candidate generation: At inference, o3 doesn’t immediately commit to a single reasoning path; it generates multiple candidate CoTs.
- Dynamic evaluation & selection: Advanced search algorithms (e.g., beam search, Monte Carlo Tree Search) evaluate these candidates for coherence and correctness, selecting the best one as the final output.
Why it matters: This method reduces errors and hallucinations while enhancing the model’s adaptability to novel challenges, ensuring robust performance on complex tasks.
Additional info:
Cost and compute scaling
- High compute demand: Extensive test-time computation allows o3 to “think” longer and produce higher-quality answers, though at a higher operational cost.
- OpenAI o3-mini variant: A smaller version, which relies less on intensive reasoning, is offered at lower prices and faster speeds, balancing cost and performance.
Source: François Chollet on X
In my opinion, OpenAI o3 is highly effective because it utilizes CoT with scaled-up RL, which demands more computing power. That’s why it is only available in their deep research at a higher price. The smaller version, like the o3-mini, which doesn’t utilize much CoT and scaled-up RL, is offered at low prices and is faster with less reasoning.
Source: Jason Wei on X
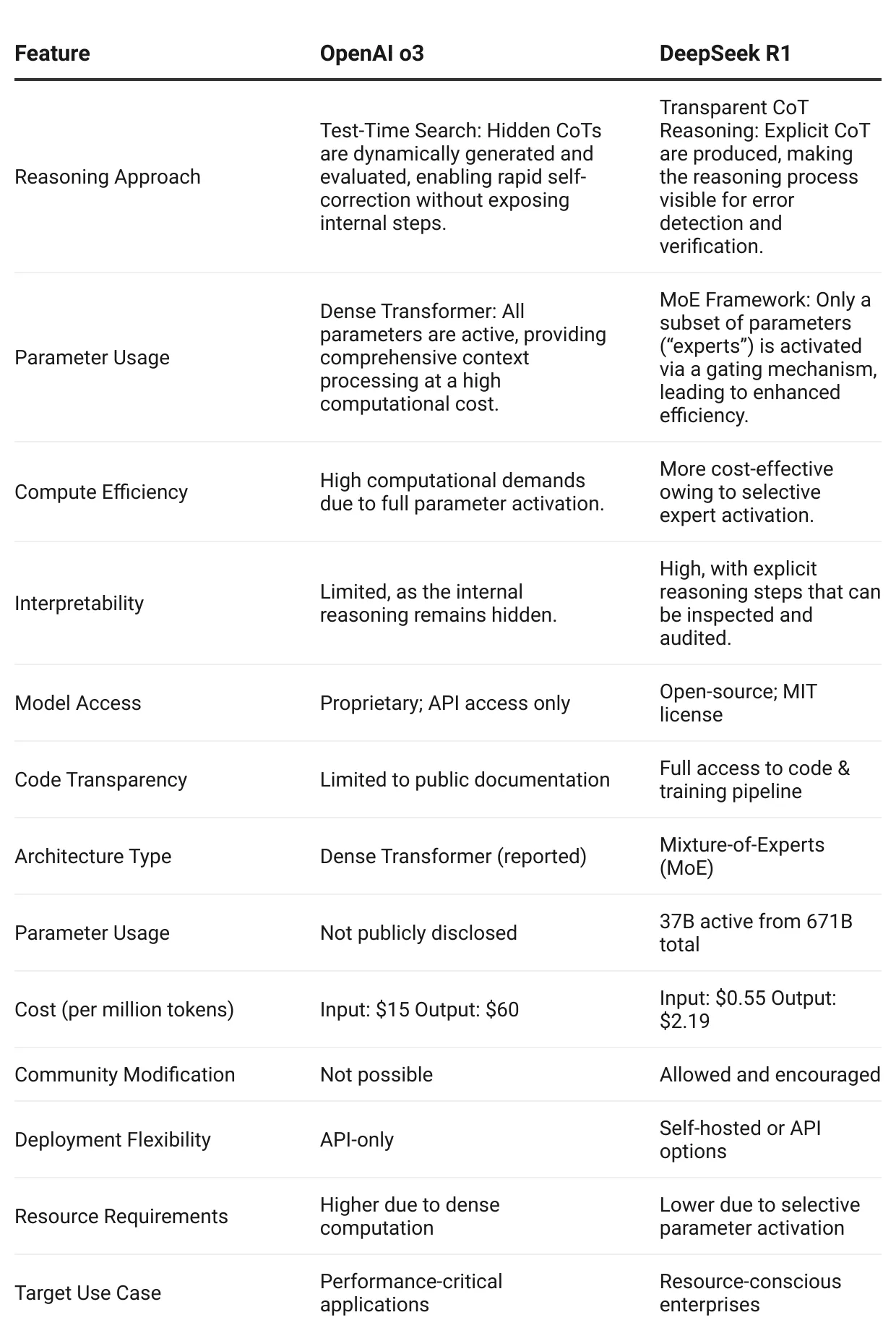
Comparing OpenAI o3 and DeepSeek R1
In this section, we will closely compare OpenAI o3 and DeepSeek R1 in various features.
Architectural differences
When comparing OpenAI o3 and DeepSeek R1, there are key differences in how they handle reasoning and parameter usage:
Reasoning approach:
- Test-time search in O3: o3 employs a dense transformer that uses test-time search to generate and evaluate multiple candidate CoTs internally without revealing them. This test-time search happens during inference.
The model “thinks” through a problem by exploring several reasoning paths and then selects the most coherent output, enhancing accuracy and adaptability at the cost of transparency - Transparent CoT reasoning in R1: DeepSeek DeepSeek R1 produces explicit CoT that is visible to users, making its reasoning process transparent and easier to audit for errors or unexpected behavior.
Parameter usage:
- O3’s dense transformer: Every parameter in O3’s dense transformer is active during processing, ensuring the model captures full context at every step, though this demands substantial computational resources.
- R1’s MoE framework: DeepSeek DeepSeek R1 uses an MoE architecture in which a gating mechanism activates only a subset of parameters (“experts”) per input. This increases efficiency by selectively utilizing the most relevant components.
Models’ Feature Comparison
Key insight: The architectural choices of these models directly impact their accessibility, cost structure, and potential business applications. DeepSeek DeepSeek R1 's open-source nature and efficient MoE architecture make it particularly attractive for businesses looking to balance performance with operational costs.
How reasoning models differ from traditional LLMs
Traditional LLMs: Strengths and limitations
Traditional large language models, such as GPT-4, have revolutionized natural language processing with their ability to generate coherent and fluent text. However, their reliance on pattern recognition instead of explicit logical inference comes with notable trade-offs:
Strengths:
- Fluency and imitation: They mimic human language by identifying and reproducing statistical patterns from vast datasets.
- Broad knowledge base: These models, trained on enormous corpora, have exposure to diverse topics and styles, making them versatile for many applications.
- Fast and scalable: Their architecture allows for rapid text generation across various prompts.
Limitations:
- Lack of explicit logical inference: Instead of reasoning step-by-step, traditional LLMs predict the next word based on probability. This means they don’t truly "understand" or logically infer the relationships between concepts.
- Difficulty with multi-step tasks: When tasks require sequential logical reasoning—such as solving complex math problems or navigating ambiguous instructions—these models can produce plausible-sounding but ultimately flawed answers.
- Ambiguity handling: They often struggle with ambiguity or problems that require a structured approach, leading to inconsistencies or errors in their responses.
- Risk of hallucination: Without an internal mechanism for explicit reasoning, traditional LLMs may generate content that appears coherent but can include incorrect or fabricated details.
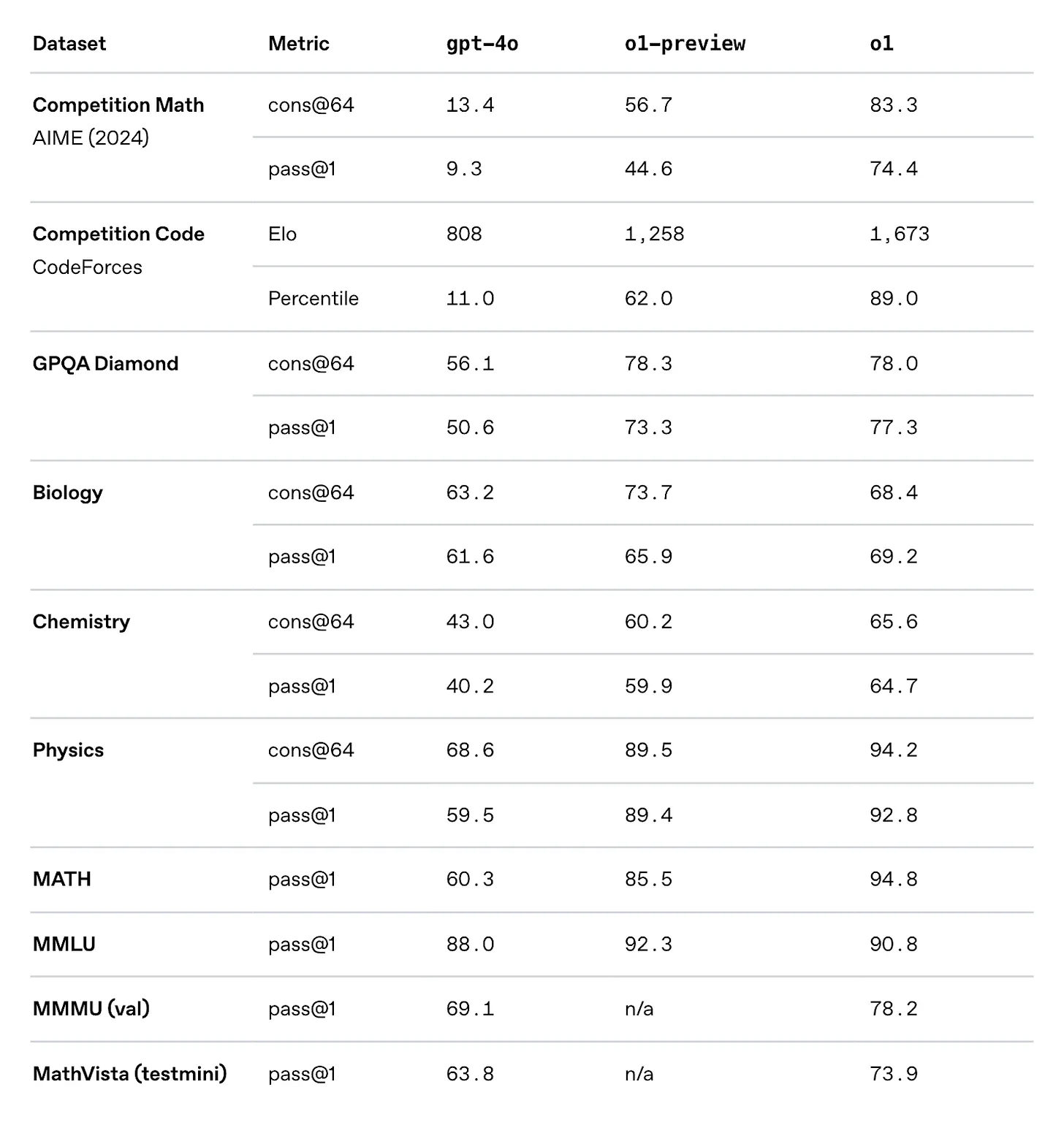
Table showing the leap that o1 (reasoning model) made over GPT-4o (traditional LLM) | Source: Learning to reason with LLMs
Key advances in reasoning models
Reasoning models have introduced several innovations that overcome the limitations of traditional LLMs. Here are the key advances:
Chain-of-Thought (CoT) reasoning:
- Step-by-step problem solving: Instead of predicting the next word solely based on learned patterns, CoT forces the model to break down complex problems into a series of intermediate reasoning steps.
- Transparency and interpretability: In models like DeepSeek R1, the chain of thought is visible, enabling users to understand how the answer is reached and easily spot errors.
Test-time search:
- Internal deliberation: Models like OpenAI o3 generate hidden chains of thought that are not exposed to the user. This internal process allows the model to “think” through a problem, refine its approach, and self-correct before producing a final answer.
- Enhanced accuracy: The model improves accuracy on multi-step tasks such as complex math problems or code generation by reasoning internally and verifying its calculations or logical steps.
Self-verification mechanisms:
- Candidate evaluation: In O3, multiple candidate solutions are generated, and a verifier model reviews them for errors—identifying miscalculations or logical inconsistencies.
- Reinforcement of correct reasoning: During training, only the best, verified reasoning paths are reinforced, ensuring the model learns to prefer robust and correct solutions.
- Deliberative alignment: This approach teaches the model explicit safety specifications and encourages it to reason over these guidelines, resulting in safer and more reliable outputs.
Real-World examples:
- Coding competitions: OpenAI o3 has demonstrated remarkable performance in competitive coding benchmarks such as Codeforces, achieving an ELO rating of approximately 2727. This significantly improves on traditional LLMs, which often fail to generate syntactically correct and logically coherent code, and on their previous reasoning model, o1.
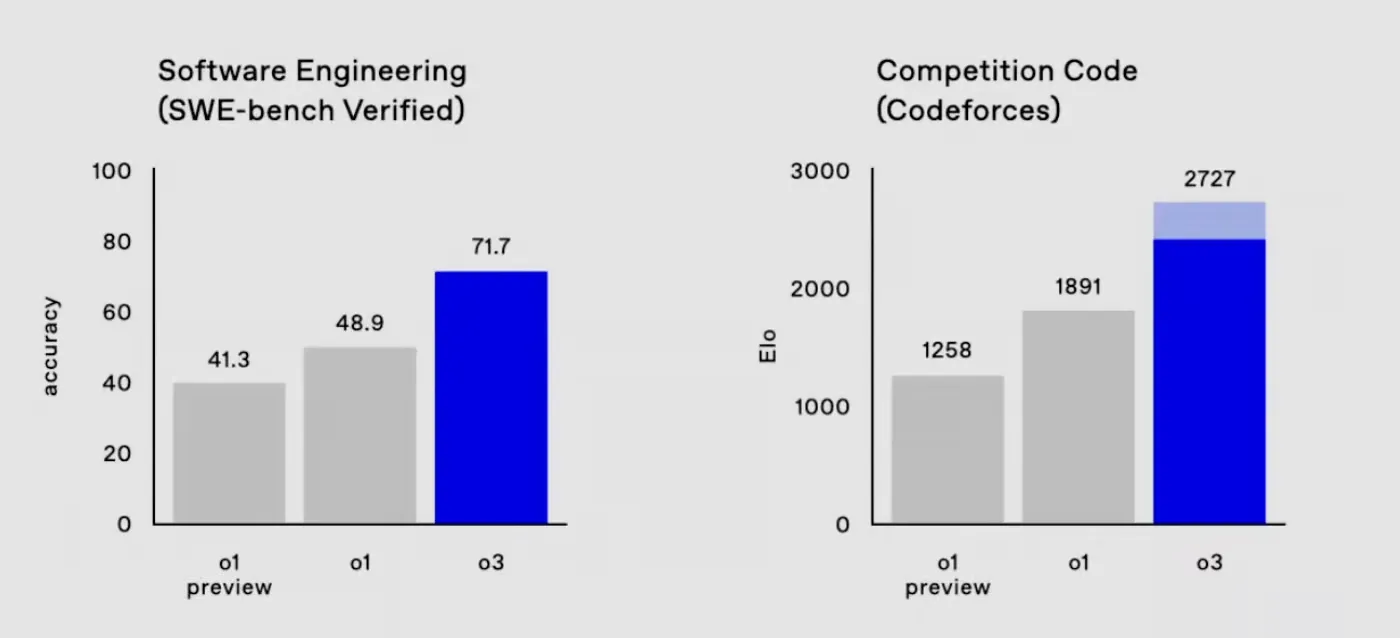
Graph showing the leap of o3 over its predecessor o1 in Software engineering and Competition Code | Source: OpenAI
- Mathematical problem solving: On benchmarks like MATH-500 and AIME 2024, reasoning models such as DeepSeek DeepSeek R1 achieve 97.3% and 79.8%, respectively. Traditional models rely on surface-level pattern matching and struggle with multi-step calculations and complex mathematical inference.
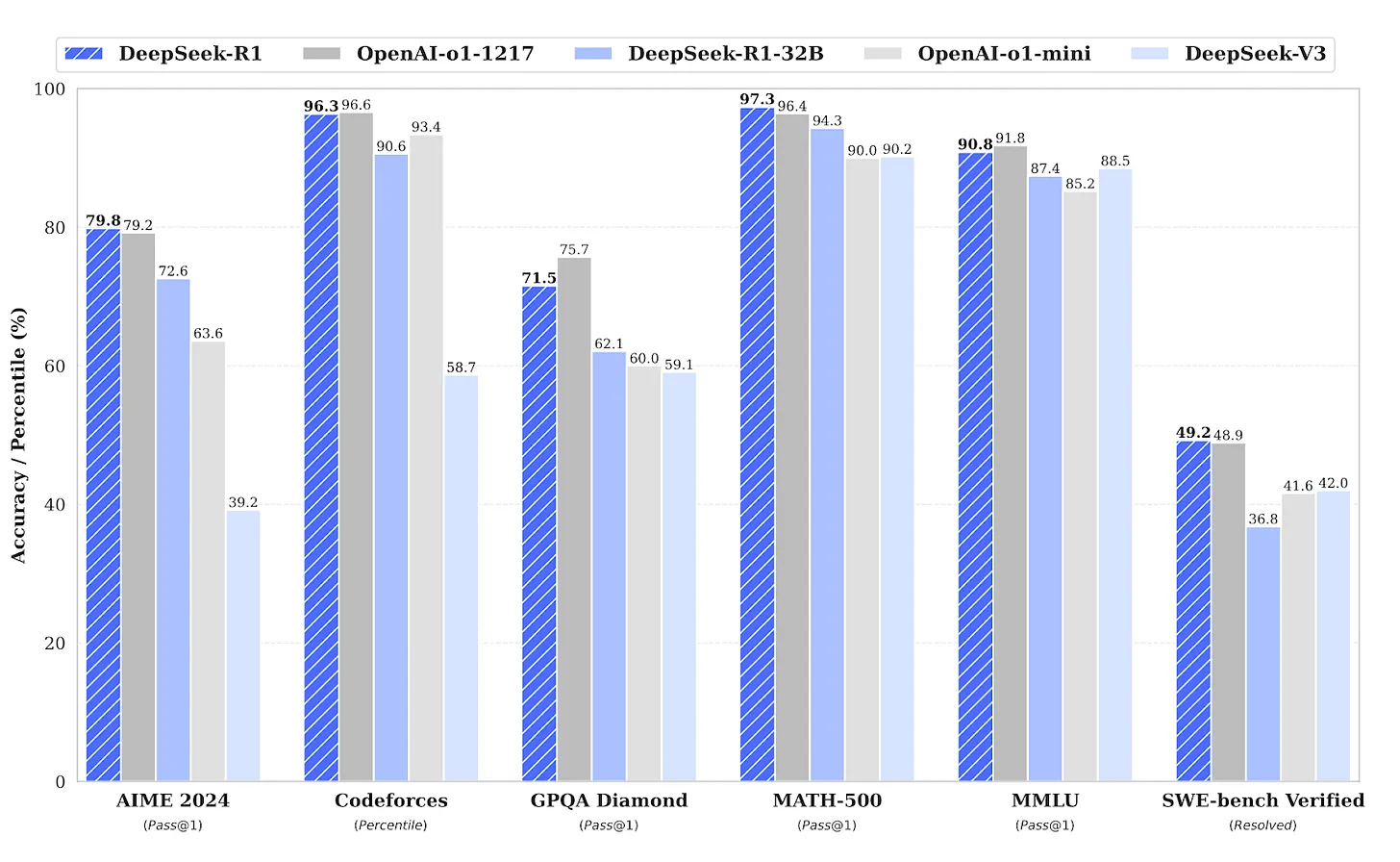
Comparison graph comparing DeepSeek R1 , o1, DeepSeek R1 32B, o1-mini, and V3 | Source: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- Scientific reasoning: On the GPQA Diamond benchmark, designed to test PhD-level science questions, OpenAI o3 scores around 87.7%. This level of performance indicates a robust internal reasoning process that traditional LLMs lack.
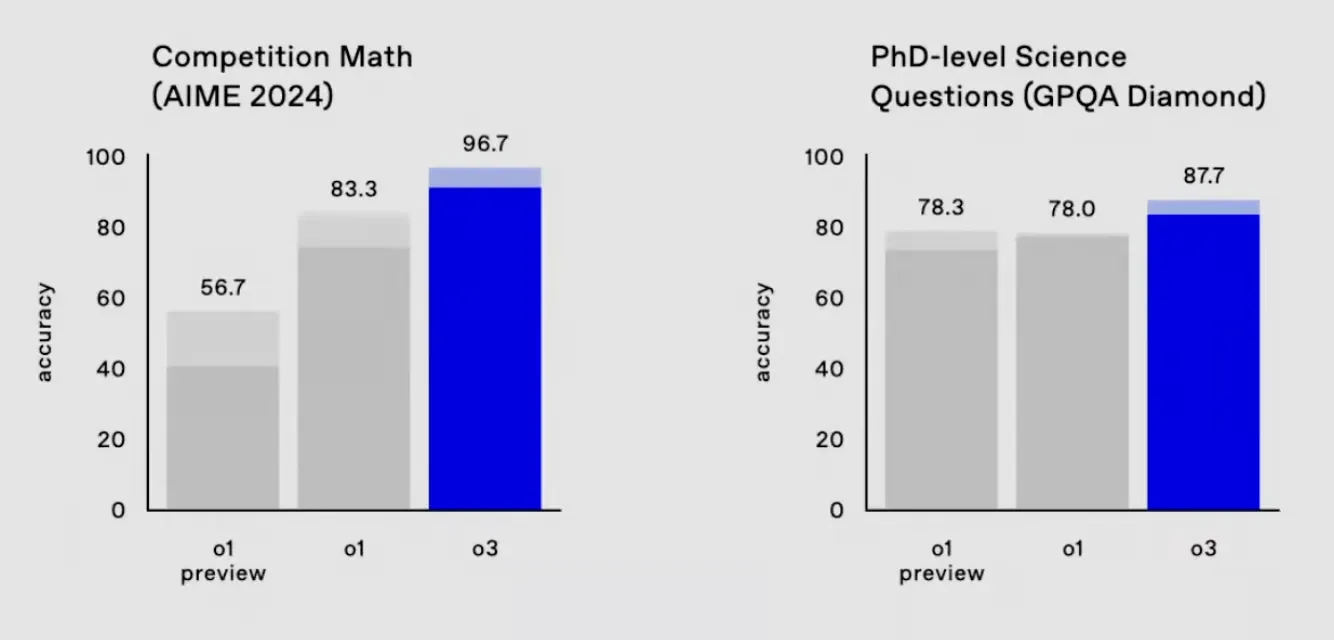
Graph showing the leap of o3 over its predecessor o1 in Competition Math and PhD-level Science | Source: OpenAI
These advances demonstrate that reasoning models can enhance their ability to tackle complex, multi-step problems by incorporating CoT, SR, and self-verification and providing more reliable, interpretable, and safer outputs. This marks a significant leap from traditional LLMs, which primarily rely on pattern recognition and often fall short when faced with ambiguity or extended logical tasks.
The role of benchmarks in evaluating reasoning models
AIME (American Invitational Mathematics Examination) 2024 Results: Measures multi-step mathematical problem-solving and logical deduction. It tests models on complex arithmetic and algebraic problems that require sequential reasoning.
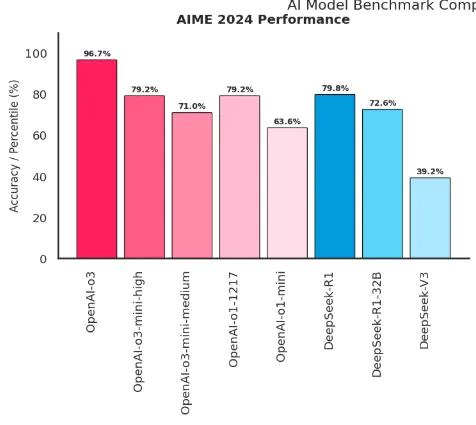
Source: Author
Codeforces (Competitive Programming): A competitive programming platform where AI models (and humans) solve complex algorithmic problems under time constraints, with performance measured by an Elo rating system that indicates a model's coding proficiency.
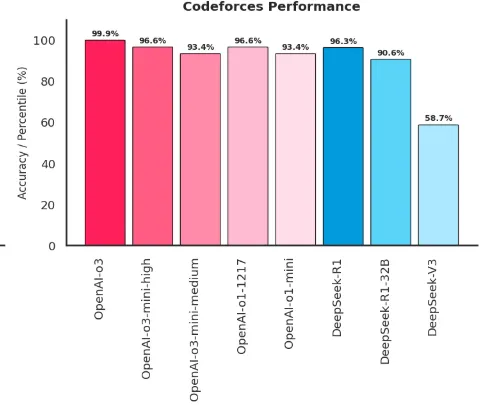
Source: Author
GPQA Diamond (Graduate-level Q&A): A benchmark consisting of PhD-level science questions across various disciplines that measures an AI model's ability to reason through and answer graduate-level academic problems.
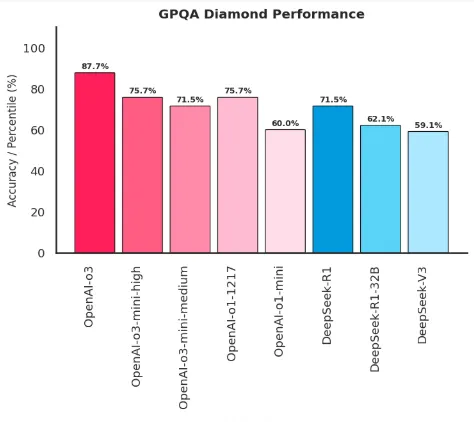
Source: Author
MATH-500 performance: Assesses advanced mathematical reasoning through diverse problems, including proofs, equations, and multi-step calculations. It emphasizes accuracy and the model’s ability to follow a logical progression through complex tasks.
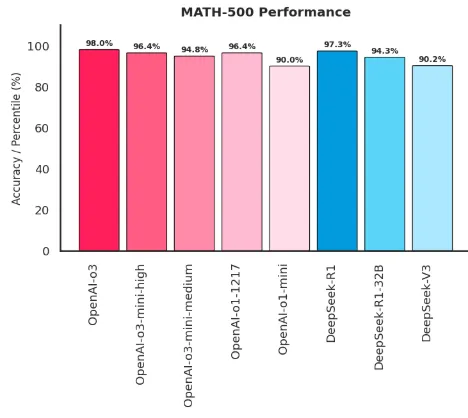
Source: Author
MMLU (Massive Multitask Language Understanding): A comprehensive evaluation benchmark that tests AI models across 57 subjects, including mathematics, science, humanities, and professional fields, to assess their broad knowledge and reasoning capabilities.
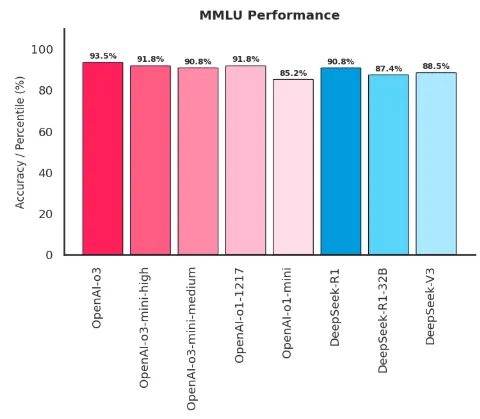
Source: Author
SWE-bench verified: It focuses on real-world software engineering tasks. It evaluates a model’s capability in code generation, debugging, and solving programming challenges, reflecting practical application skills in software development.
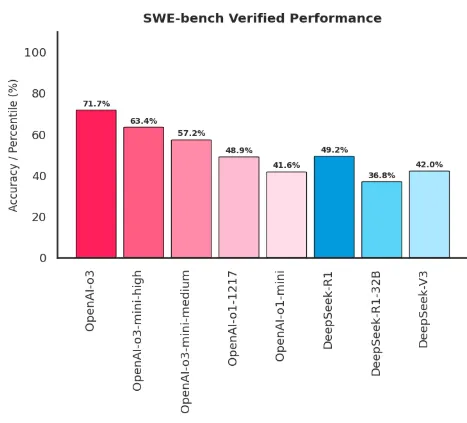
Source: Author
Key observations:
- 1o3 consistently outperforms all other models across benchmarks
- 2o3-mini variants show strong scaling with increased reasoning effort (medium to high)
- 3o3-mini-high often matches or exceeds o1-1217's performance
- 4Software engineering tasks (SWE-bench) show the largest performance gap between o3 and other models
- 5Mathematical reasoning tasks show the highest overall scores across models
o3 and DeepSeek R1 on ARC-AGI evaluation
ARC-AGI (Abstraction and Reasoning Corpus for Artificial General Intelligence) is a critical benchmark designed to test AI systems' ability to adapt to novel, unseen problems rather than relying on memorization.
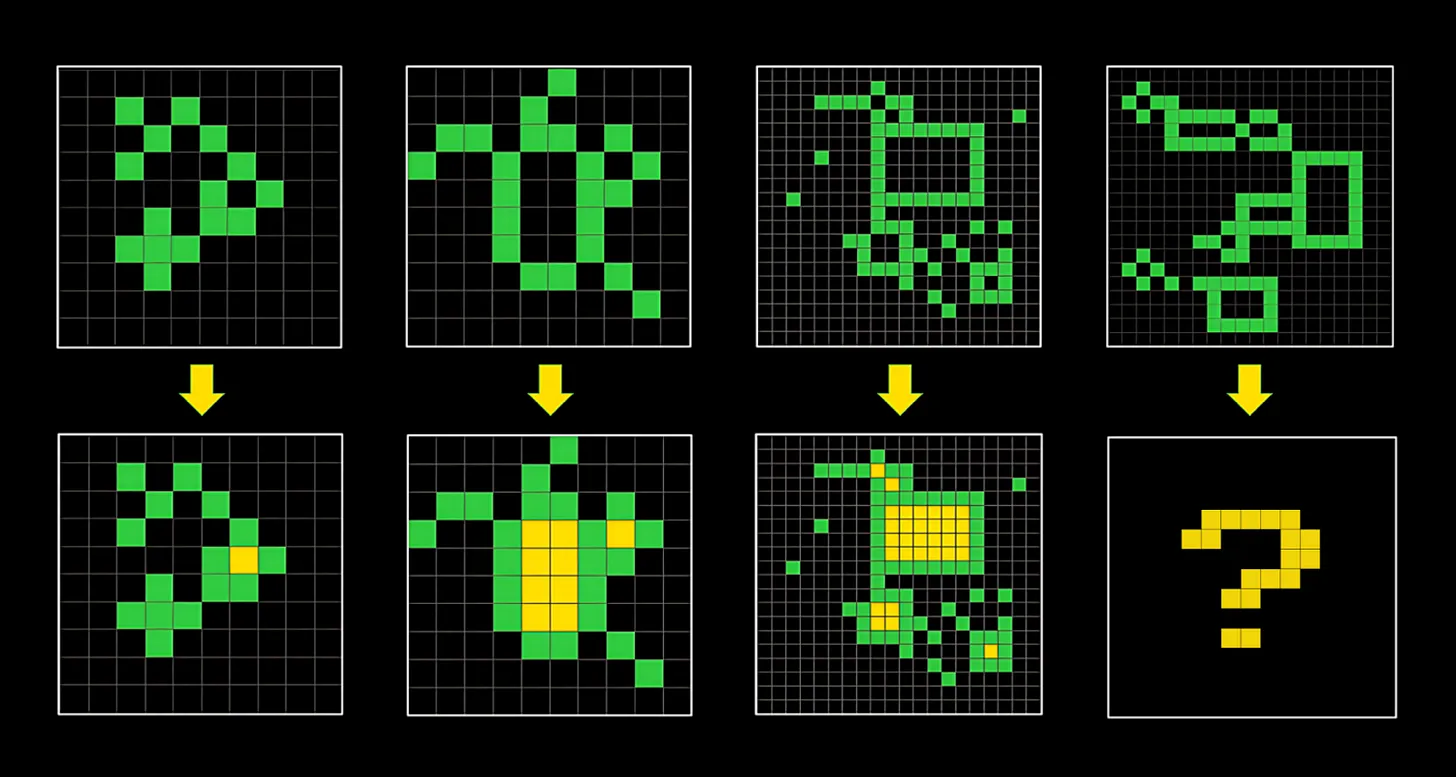
The ARC-AGI dataset consists of puzzle-like input-output pairs in a grid | Source: ARC Prize
Here are the key aspects:
- Purpose: To measure an AI system's ability to demonstrate generalization power and reasoning capabilities across unseen tasks
- Structure: Consists of visual grid-based tasks where AI must determine transformation rules from input/output examples
- Datasets:
• Semi-Private Eval: 100 private tasks for assessing overfitting
• Public Eval: 400 public tasks - Historical context: From 2020 to 2024, progress was minimal:
• GPT-3 scored 0%
• GPT-4 scored near 0%
• GPT-4o reached only 5%

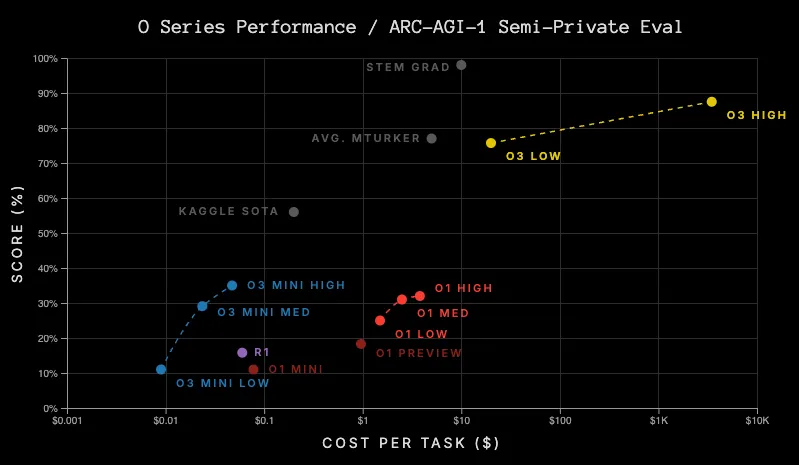
The graph describes that the ‘o’ series performance score will increase as cost per task increases. | Source: ARC Price
To reiterate some key highlights:
- Compute vs cost: o3 achieves higher accuracy but at a significantly higher computational cost
- Architectural differences:
• o3 focuses on test-time search and sampling
• DeepSeek R1 emphasizes efficient architecture with MoE - Accessibility:
• DeepSeek R1 is open-source and more cost-effective
• o3 is closed-source but shows superior performance - Generalization:
Both models demonstrate significant improvements over previous LLMs in handling novel tasks
Why are reasoning models the future of AI scaling?
Enhanced capabilities
Reasoning models represent a paradigm shift in AI, as they empower systems with the ability to engage in human-like, multi-step reasoning, leading to smarter decision-making agents. These advanced models are not merely pattern predictors—they are designed to internally deliberate, self-correct, and arrive at well-justified conclusions. Here’s why they stand out:
Smarter decision-making:
- Multi-step reasoning: By generating detailed CoT, reasoning models can break down complex problems into manageable steps.
This enables them to handle ambiguous or multi-faceted tasks that traditional LLMs struggle with. - Self-correction and verification: Mechanisms like simulated reasoning and self-verification allow these models to check their work and adjust their outputs in real-time, leading to more accurate and reliable decisions.
Real-world applications:
- Healthcare diagnostics: Reasoning models can analyze patient data, interpret medical literature, and integrate complex clinical guidelines to suggest accurate diagnoses and treatment plans.
- Autonomous systems: The ability to reason through dynamic environments and unforeseen scenarios is crucial for safety and efficiency in robotics and self-driving vehicles.
- Scientific research: They assist researchers by generating hypotheses, interpreting experimental data, and even simulating complex scientific phenomena, thereby accelerating discovery.
- Other critical domains: These models' robust decision-making capabilities also benefit applications in finance, legal reasoning, and personalized education.
These models set a new standard for AI by scaling reasoning capabilities. They improve performance on traditional benchmarks and open the door to applications that require deep understanding and adaptive decision-making, paving the way for AI systems that can truly function as intelligent, autonomous agents.
Scaling intelligence
Reasoning models are paving the way for a new era of scaling intelligence by combining efficiency with a deeper understanding. Here’s how:
Combining efficiency with depth:
- Efficient compute usage: Techniques like the MoE in DeepSeek DeepSeek R1 enable selective parameter activation, meaning only the most relevant parts of the model are used for each task. This leads to more efficient use of computational resources.
- Deep, multi-step reasoning: Models such as OpenAI o3 employ simulated reasoning and extended CoT to tackle complex problems step by step. This not only enhances accuracy but also allows the model to self-correct and refine its answers before finalizing them.
- Self-verification mechanisms: Both o3 and DeepSeek R1 incorporate internal verification processes. For example, o3 uses a verifier model to check candidate solutions, ensuring that the final output is robust and reliable. This combination of efficiency and deep reasoning is key to scaling intelligence.
Pathways for future improvement:
- Extended CoT scaling: Research is exploring how longer and more detailed CoT can further boost performance, allowing models to solve even more complex problems with multiple layers of reasoning.
- Enhanced distillation techniques: Distillation methods are being refined to transfer advanced reasoning abilities from large models to smaller, more accessible ones without significant loss in performance.
- Improved safety and alignment: Ongoing work in deliberative alignment explicitly teaches models to reason over safety policies, ensuring that they remain safe and aligned with human values as their reasoning depth increases.
- Cross-model guidance and representation engineering: Researchers are investigating how models can leverage insights from one model to improve another (such as via cross-model guidance) and how tweaking internal representations can further enhance reasoning capabilities.
- New benchmarks and evaluation metrics: As reasoning models scale, novel benchmarks (like ARC AGI-Pub) are being developed to challenge and measure their capabilities in more diverse, real-world scenarios. This provides a continuous feedback loop for improvement.
These advances demonstrate that reasoning models are more capable and set a scalable framework for future AI developments. They represent a fundamental shift toward systems that can perform deep, human-like reasoning while operating efficiently—a crucial step toward truly intelligent and versatile AI.
Challenges and limitations of reasoning models
Computational costs
While reasoning models like o3 and DeepSeek R1 deliver superior accuracy, their token-intensive processes create critical trade-offs:

Table showing the computational cost of both the models | Source: OpenAI o3-mini vs. DeepSeek R1: Which one to choose?
Table showing the computational cost of both the models | Source: OpenAI o3-mini vs. DeepSeek R1: Which one to choose?
Key challenges:
- CoT overhead: Generating reasoning steps can increase token usage by 3–5x compared to direct answers. For example, solving a math problem might require 1,200 tokens instead of 300.
- Latency vs intelligence: o3’s high-reasoning mode takes 7.7 seconds for 100K-token outputs, while R1’s open-source design struggles with real-time applications.
- Energy demands: Training o3 required 1.2M A100 GPU hours compared to R1’s 2.66M H800 GPU hours, highlighting the carbon footprint of advanced reasoning models.
This cost-reasoning gap forces businesses to choose to prioritize accuracy (o3) for mission-critical tasks or optimize budgets (R1) for high-volume workflows.
Domain-specific limitations
Despite breakthroughs, reasoning models still face hurdles in niche applications:

Anton P. said on X that o3-mini-high reasoned in Chinese | Source: ChatGPT o3-mini-high
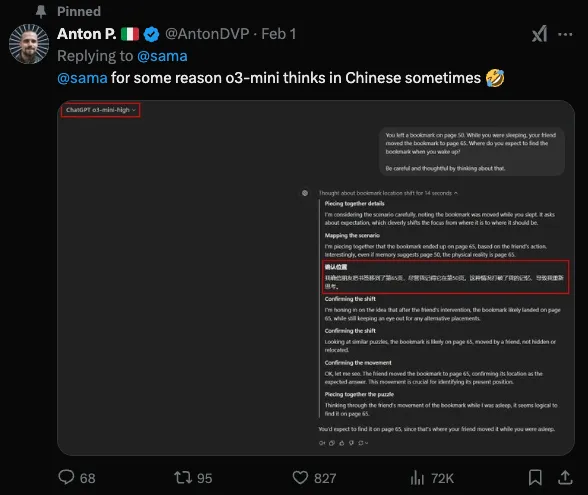
Tweet from Anton P on X about mixing language while reasoning | Source: X
Critical weaknesses:
- The simple query paradox: Both models treat basic prompts (e.g., “Convert 5km to miles”) as complex problems, wasting resources.
- Safety vs performance: R1’s safety RL training reduced Chinese SimpleQA accuracy by 12%, showing alignment challenges.
- Context fragmentation: While o3 supports 200K-token windows, multi-turn dialogues often break the logical flow.
What to expect in the future
The future of the reasoning models will be heavily dependent on Reinforcement Learning.
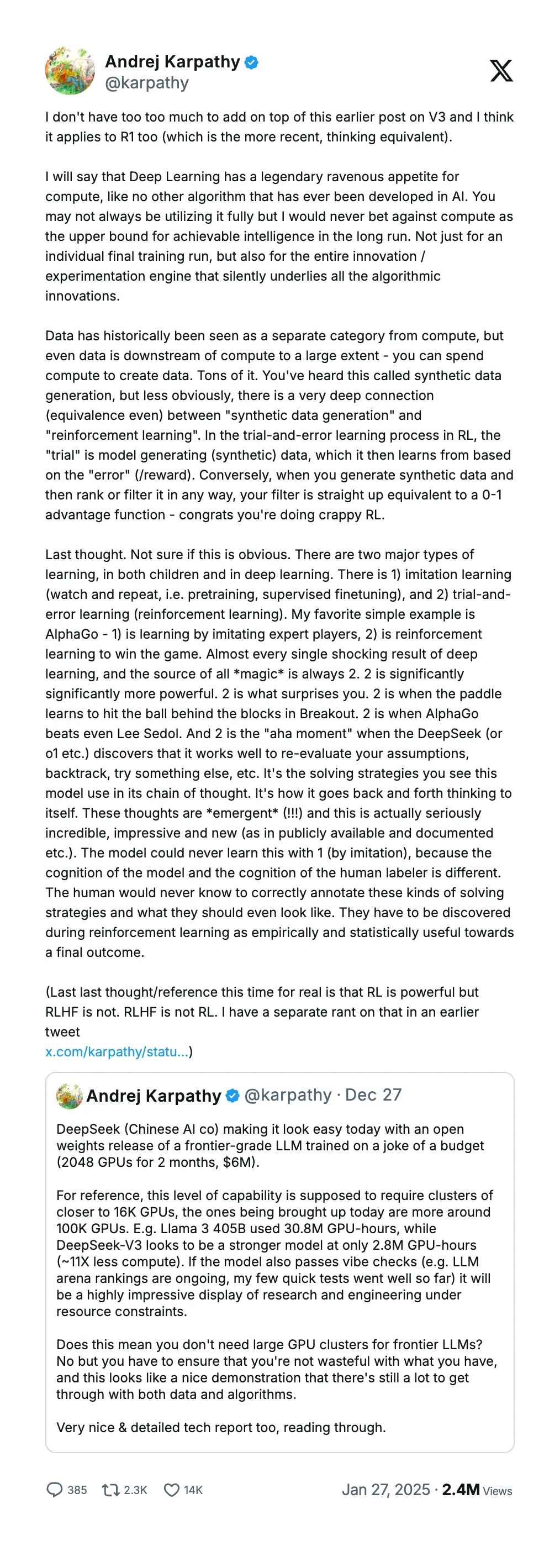
Andrej Karpathy on X
AlphaGo from Google Deepmind (formerly known as Deepmind) showed us how RL can achieve human-level intelligence in the game of Go. In March 2016, it defeated Lee Sedol with a 4-1 score.
Now, we are in an intelligence age, and o3 and DeepSeek R1 are again using RL to approach human-like reasoning.
Conclusion
In this article, we saw that reasoning models like OpenAI's o3 and DeepSeek's DeepSeek R1 are pivotal in AI development. These models don't just process information—they think through problems step-by-step, verify their work, and adapt to novel challenges. For businesses building AI products, this represents both an opportunity and a decision point.
While o3 demonstrates superior performance across benchmarks, particularly in code generation and mathematical reasoning, DeepSeek R1 's open-source nature and cost efficiency make it an attractive alternative for scale-conscious organizations. The choice between them ultimately depends on your specific needs:
- If your application demands the highest possible accuracy and can absorb higher compute costs, o3's architecture may be the better fit
- If you need to balance performance with scalability and want the flexibility of an open-source solution, DeepSeek R1 's MoE approach could be optimal
What's clear is that reasoning capabilities in AI are no longer just research concepts—they're becoming essential features for production systems. As these models continue to evolve, they'll enable increasingly sophisticated applications while becoming more efficient and accessible.
The real question isn't whether to adopt reasoning models but how to strategically integrate them into your AI roadmap. The future of AI isn't just about bigger models—it's about smarter ones.
References
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23