
Every AI product needs reliable evaluation methods. As LLM capabilities expand, traditional metrics fall short of capturing the nuance in model outputs. Enter LLM judges—specialized models fine-tuned to evaluate the quality of other language models with human-like discernment. This approach is transforming how teams assess and improve their AI systems.
LLM judges operate through preference learning, comparing model outputs to predict human preferences. Through specialized architectures and training techniques, these models can evaluate responses across multiple dimensions including helpfulness, accuracy, and safety. The most effective implementations incorporate both pairwise comparisons and direct scoring methodologies.
For product teams, implementing judge models offers concrete benefits:
- More consistent evaluations at scale
- Detailed qualitative feedback with reasoning
- Ability to assess complex, open-ended tasks where traditional metrics fail
These capabilities are especially valuable during rapid iteration cycles when human evaluation becomes impractical.
Core Topics:
- 1
LLM Judge Fundamentals
Technical architecture and evaluation methodologies - 2
Human Preference Alignment
Techniques for calibrating judge models to human standards - 3
Building Robust Datasets
Strategies for creating effective training data - 4
Advanced Finetuning Methods
Specialized approaches for judge model training - 5
Practical Frameworks
Implementing MT-Bench and Chatbot Arena evaluations
How LLM judges fundamentally transform AI evaluation
Large language model (LLM) judges represent a paradigm shift in AI evaluation. These specialized models, fine-tuned to assess the quality of other LLMs' outputs, are revolutionizing how we measure AI performance through their ability to provide nuanced, human-like feedback.
Technical architecture of LLM judges
Unlike general-purpose LLMs, judge models are specifically fine-tuned on datasets of human preferences and rankings. They function by comparing model outputs, often in a pairwise format, and predicting which response humans would prefer. This specialized training enables them to evaluate responses based on multiple dimensions like helpfulness, accuracy, and safety.

The three overarching abilities of MT-Benchmark | Source: MT-Bench-101: A Fine-Grained Benchmark for Evaluating Large Language Models in Multi-Turn Dialogues
Modern evaluation frameworks like MT-Bench leverage these judge models to assess multi-turn conversations and diverse LLM capabilities. The effectiveness of these judges hinges on careful calibration and bias mitigation techniques.
Evaluation methodologies
LLM judges employ two primary evaluation approaches:
- 1
Pairwise comparison
Models evaluate two responses side-by-side to determine which one humans would likely prefer. This method excels at relative quality assessment but requires multiple evaluations. - 2
Direct scoring
Judges provide numerical scores for individual responses based on defined criteria. This approach offers efficiency at scale but may lack comparative context.
Research has shown that judges with high percent agreement can still assign vastly different scores. Models like Llama-3 70B and GPT-4 Turbo demonstrate excellent alignment with humans, yet sometimes rank exam-taker models differently than human evaluators would.
Implementation workflow
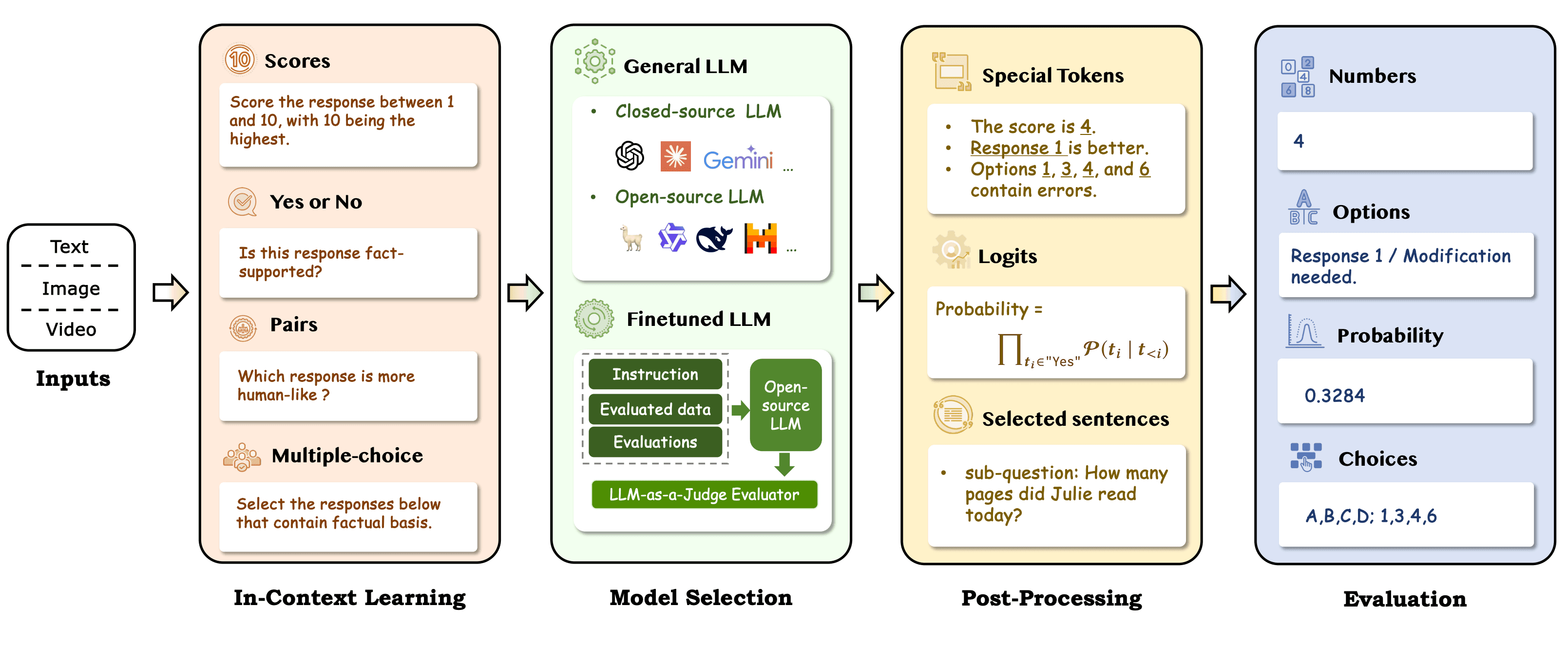
Overview of LLM as judge workflow | Source: A Survey on LLM-as-a-Judge
Implementing LLM judges involves a structured process:
- 1Task definition with clear evaluation criteria
- 2Selection of appropriate judge model
- 3Structured prompt design that includes:
• Task description
• Evaluation criteria
• Input given to evaluated model
• Output generated by evaluated model
The judge then provides a structured assessment typically including numerical scores and qualitative feedback with reasoning for the evaluation.
Scoring protocols
LLM judges use systematic scoring frameworks to ensure consistent evaluations. These typically involve:
- Defined scoring scales (e.g., 1-10)
- Multi-criteria evaluation across dimensions like accuracy, coherence, and relevance
- Statistical reliability measures to account for evaluation variability
One single-sentence paragraph stands out as particularly important: LLM judges have become essential tools for model development, alignment research, and quality assurance in commercial LLMs.
This approach enables more reliable evaluation of complex, open-ended tasks where traditional metrics fall short, providing deeper insights into model performance than automated metrics alone. As we continue to develop and refine these judge models, their ability to provide accurate, human-aligned evaluations becomes increasingly valuable for advancing AI systems.
Human preference alignment techniques for judge models
As we explore more specialized aspects of LLM judges, understanding how they align with human preferences becomes crucial for their effectiveness as evaluation tools.
Understanding LLM judges

An open-sourced LLM can be fine-tuned on a human-preferred dataset/criteria to establish them as evaluators | Source: A Survey on LLM-as-a-Judge
LLM judges are specialized language models fine-tuned to evaluate the quality of responses from other LLMs based on human preferences. These judges function by comparing model outputs, often in a pairwise format, and predicting which response humans would prefer. The effectiveness of these judge models depends on careful calibration, domain-specific training, and bias mitigation techniques.
Preference learning methodologies
Recent advancements include specialized fine-tuning methods that incorporate diverse human preferences. These approaches often involve training on datasets of human preferences and rankings of model responses. The process typically begins with collecting human feedback on model outputs, followed by modeling these preferences to align the judge with human evaluations.
Contrastive learning has emerged as a powerful technique. It improves representation alignment by teaching models to differentiate between preferred and non-preferred responses. This method helps judge models develop a deeper understanding of what makes a response valuable to humans.
Human versus LLM evaluation capabilities
While LLM judges offer efficiency and scalability, comparing their performance with human evaluators reveals interesting patterns. Modern evaluation frameworks like MT-Bench and Chatbot Arena employ these judge models to assess multi-turn conversations and diverse capabilities.
Human evaluators excel at detecting nuanced ethical issues and cultural context. LLM judges, however, can process vast amounts of data consistently. Studies show that both Llama-3 70B and GPT-4 Turbo demonstrate excellent alignment with human preferences, though they may differ in ranking models.
Mitigating bias in judge models
Two critical biases affect judge model training:
These bias mitigation strategies are essential for developing fair and reliable judge models that accurately reflect human preferences.
Future directions in judge model alignment
Creating more robust judge models requires continued refinement of preference learning techniques. Explicit reasoning steps during evaluation show promise in improving alignment. Multi-criteria frameworks that simultaneously consider helpfulness, accuracy, and safety also enhance judge performance.
As judge models become more sophisticated, they will increasingly serve as essential tools for model development, alignment research, and quality assurance in commercial LLM deployments. The continuous improvement of these alignment techniques represents a critical path forward in developing more effective and reliable evaluation systems.
Building robust preference datasets for judge training
Having explored the importance of human preference alignment, we now turn to the critical foundation of effective judge models: the datasets used to train them.
The importance of diverse data
Creating strong preference datasets is crucial for training effective LLM judges. These datasets should maximize diversity to ensure comprehensive model evaluation. Collecting samples from varied sources helps capture a wide range of language patterns and response types.
The quality of judge models depends directly on the breadth of their training data. Models trained on limited datasets often develop blind spots in their evaluation capabilities.
Implementing scalable annotation frameworks
Developing structured annotation pipelines enables efficient preference data collection. These frameworks should combine crowdsourced human evaluations with synthetic data generation approaches.
Hybrid labeling systems leverage both human judgment and algorithmic assistance. This combination allows for greater scale while maintaining quality standards in the annotation process.
Establishing clear guidelines for annotators improves consistency and reduces subjectivity in preference labeling. Teams should develop detailed documentation to serve as a reference point during the annotation process.
Balancing human and synthetic data
Both crowdsourced and synthetically generated data offer unique advantages for judge training:
Research shows that combining these approaches yields better results than either method alone. The ideal ratio depends on specific evaluation needs and resource constraints.
Synthetically generated data can help fill gaps in human-annotated datasets. However, quality control remains essential to prevent propagating biases or errors in synthetic examples.
Practical implementation strategies
- 1Start with a representative subset of test cases when building preference datasets
- 2Focus on capturing diverse query types and response variations that reflect real-world usage patterns
- 3Write clear annotation guidelines that define evaluation criteria precisely
- 4Test these guidelines on sample data to ensure they capture all relevant use cases and edge cases
- 5Consider setting up communication channels between annotators to discuss challenging examples
Resource optimization for startups
Smaller organizations can develop effective preference datasets without massive resources. Begin with focused datasets targeting specific evaluation needs rather than attempting comprehensive coverage immediately.
Leverage open-source datasets as starting points, then augment with custom examples reflective of your specific use cases. This approach reduces initial investment while maintaining relevance.
Implement continuous learning loops that incorporate new examples over time. This iterative approach allows gradual improvement of judge models without requiring large upfront data collection efforts. With these robust datasets in place, organizations can move on to implementing more advanced finetuning methodologies for their judge models.
Advanced finetuning methodologies for LLM judges
With a solid foundation of preference datasets established, we can now explore the specialized techniques that transform these data collections into effective judge models.
Large language model judges serve as specialized evaluators trained to assess the quality of responses from other LLMs based on human preferences. The effectiveness of these judge models hinges on sophisticated finetuning techniques that enable precise evaluation capabilities.
Specialized architectures for judge models
Judge models require unique architectural considerations compared to standard LLMs. Recent advancements focus on calibrating these models to evaluate multi-turn conversations and capture diverse human preferences. The most effective approaches incorporate explicit reasoning steps before producing a final assessment. This allows judges to provide more transparent evaluations by explaining their rationale.
Some implementations integrate multi-criteria frameworks that separately assess helpfulness, accuracy, and safety before combining these scores. This approach mirrors how human evaluators consider multiple dimensions when evaluating text quality.
Training with diverse preference data
The quality of training data significantly impacts judge model performance. Modern finetuning methodologies emphasize incorporating a wide spectrum of human preferences rather than relying on a narrow set of evaluations.
Specialized training processes involve exposing models to pairwise comparisons of responses, teaching them to predict which response humans would prefer. This creates more robust judge models capable of generalizing across different types of content and contexts.
Studies show that judges with high percent agreement can still assign vastly different scores, highlighting the importance of training on diverse preference datasets. For example, research revealed that JudgeLM-7B and lexical judges can outperform larger models like Llama-3 70B in certain ranking tasks despite having lower human alignment.
Multi-turn evaluation techniques
One of the most challenging aspects of LLM evaluation is handling multi-turn conversations. Advanced judge models employ specific architectural modifications to maintain context awareness across multiple exchanges.
Rather than evaluating each response in isolation, these models track the coherence and relevance of exchanges throughout an entire conversation. This mimics how humans judge dialogue quality by considering the overall flow and appropriateness of responses in context.
Context retention mechanisms allow judge models to reference earlier parts of a conversation when evaluating later responses. This improves their ability to detect inconsistencies or declining quality in longer interactions.
Reward modeling vs. RLHF approaches
Two primary methodologies dominate judge model training:
The choice between these approaches depends on specific evaluation needs, with some implementations combining elements of both for more robust judge models. Having explored these advanced finetuning methodologies, we can now examine how these judge models are implemented in real-world evaluation frameworks.
Implementing MT-Bench and Chatbot Arena evaluation frameworks
Now that we've explored the foundational aspects of LLM judge training, let's examine how these judges are deployed in two leading evaluation frameworks that have become industry standards.
MT-Bench and Chatbot Arena offer complementary approaches to evaluating LLM capabilities:
Technical implementation considerations
Both frameworks require careful calibration to ensure reliable results:
For MT-Bench:
- Scoring mechanism uses specialized LLM judges fine-tuned on human preference data
- Incorporates explicit reasoning steps before assigning scores
- Requires prompt templates that encourage step-by-step evaluation
- Needs consistent application of criteria
For Chatbot Arena:
- Requires robust anonymization protocols
- Uses randomized model pairing to prevent bias
- Must track win rates and battle counts meticulously
- Needs thousands of comparisons to ensure statistical significance
Bias mitigation strategies
Successful implementations incorporate several bias reduction techniques:
- Both frameworks employ diverse prompts across multiple domains
- MT-Bench uses multi-criteria evaluation frameworks
- Factors like helpfulness, accuracy, and safety are considered independently
- Cross-model calibration prevents favoring outputs similar to generation style
- Regular re-calibration against human evaluations maintains alignment
Continuous evaluation of architecture
Production deployments benefit from a monitoring pipeline that automatically samples model outputs for evaluation. This involves:
- 1A dedicated evaluation service that runs independently from the main inference pipeline
- 2Periodic benchmarking against reference models to detect performance drift
- 3Integration with monitoring dashboards to visualize performance trends
This architecture enables teams to continually assess model quality as prompts evolve and new capabilities are added.
With these frameworks in place, organizations can establish consistent, scalable evaluation systems that provide valuable insights into their models' performance and guide ongoing improvements.
Comparing evaluation methods: Human, LLM judges, and traditional metrics
Each evaluation method has strengths and weaknesses. Understanding these differences helps teams choose the right approach for their needs.
Evaluation method comparison
The table below compares key characteristics across three main evaluation approaches:
This comparison shows why LLM judges have become popular. They offer a good balance between the nuance of human evaluation and the efficiency of automated metrics.
Traditional metrics are fast and cheap but miss the subtleties in language. Human evaluators understand nuance but can't scale. LLM judges fill this middle ground.
Teams often mix these approaches. They might use automated metrics for quick checks, LLM judges for regular evaluation, and human reviewers for critical decisions.
LLM Judges in Practice: Adoption by Major AI Labs (2025)
By 2025, LLM judges have moved from research ideas to standard practice in the AI industry. Leading labs now use these systems throughout the LLM lifecycle.
How Major Labs Use LLM Judges
Different AI labs have taken unique approaches to LLM judge development:
- Meta AI focuses on improving judge reasoning with their EvalPlanner system. This tool uses a three-stage process:
• Creating an evaluation plan for each task
• Following the steps in the plan
• Making a final judgment - OpenAI develops benchmarks and frameworks like PaperBench. This benchmark tests if AI can replicate research papers. They also created the OpenAI Evals framework for running evaluations.
- Google DeepMind tests the limits of judges with complex math problems. Their USAMO 2025 Evaluation showed current LLM judges struggle with formal mathematical proofs.
- Anthropic pioneered using LLM judges for safety with their Constitutional AI work. This approach uses AI to critique itself based on safety principles.
Adaline.ai to implement LLM as Judge
Adaline.ai offers various evaluation tools, including an LLM as a judge ( or LLM rubric) to evaluate the output against the evaluation criteria you describe.

While working with the LLM rubric, you are required to:

- 1Provide a title for your evaluation.
- 2Select the dataset that will serve as the ground truth for the LLM to evaluate the output.
- 3Describe the evaluation criteria.
Once done, you can then run your evaluation.

The judges will thoroughly evaluate the LLM output with the dataset you provided while adhering to the evaluation criteria that you’ve described. Once the evaluation is completed, Adaline.ai will provide you with a thorough analysis of the entire execution. It will essentially indicate which prompts were successful and which ones were not, allowing you to make changes and iterate on your prompts effectively.

Adaline.ai allows you to actively iterate and evaluate your prompts before deploying them. As such, it offers a seamless experience for writing, iterating, and evaluating your prompt for your product.
Common Benchmarks
Popular benchmarks include:
- MT-Bench for conversations
- Chatbot Arena for model competitions
- RewardBench for testing judges themselves
Industry Applications
Companies use LLM judges for several key tasks:
- Model Alignment: Making AI follow human values and instructions
- Safety Checking: Finding harmful, biased, or toxic outputs
- Performance Testing: Comparing different models or prompts
- Skill Assessment: Evaluating coding, math, and reasoning abilities
- RAG Evaluation: Checking if retrieved information is relevant and accurate
This widespread adoption shows how valuable LLM judges have become for AI development and safety.
Conclusion
LLM judges represent a significant advancement in AI evaluation methodology. By leveraging specialized models fine-tuned on human preferences, teams can now evaluate complex, open-ended tasks with unprecedented consistency and scale. The frameworks presented—from preference data collection to advanced finetuning techniques—provide a comprehensive approach to implementing effective evaluation systems.
The most successful implementations share common elements:
- Diverse training data
- Bias mitigation strategies
- Multi-criteria evaluation frameworks
Position and verbosity biases remain significant challenges, requiring specific architectural considerations during judge model development.
For product teams, these techniques translate to faster iteration cycles and more reliable quality assessment: