Language model distillation is an innovative technique that efficiently transfers advanced reasoning capabilities from large (teacher) models to smaller (student) architectures. The primary motivation is dramatically reducing computational costs while maintaining strong performance on complex inference tasks. By leveraging knowledge distillation, model developers can reduce parameter counts and memory requirements with minimal degradation of logical coherence and factual accuracy.
However, distillation still faces challenges around efficient knowledge transfer, avoiding reasoning shortcuts, and balancing inference latency trade-offs.
This article will dive deep into,
- 1Traditional knowledge distillation basics and teacher-student model paradigm
- 2LLM-specific distillation techniques, including TAID and temperature scaling
- 3Comparison between traditional and LLM distillation approaches
- 4A step-by-step guide using the NVIDIA NeMo framework
- 5Advanced Features like CoT and reinforcement learning
Let’s start.
1. Foundations of LM distillation
In this section, I will discuss what traditional or standard knowledge distillation is compared to LLM knowledge distillation.
1.1 Knowledge Distillation
Let’s assume a teacher with extensive knowledge and a bright student eager to learn. The teacher has mastered complex subjects but wants to pass on this knowledge efficiently without overwhelming the student. The central concept of knowledge distillation in language models is to transfer the abilities of a large "teacher" model to a smaller "student" model.
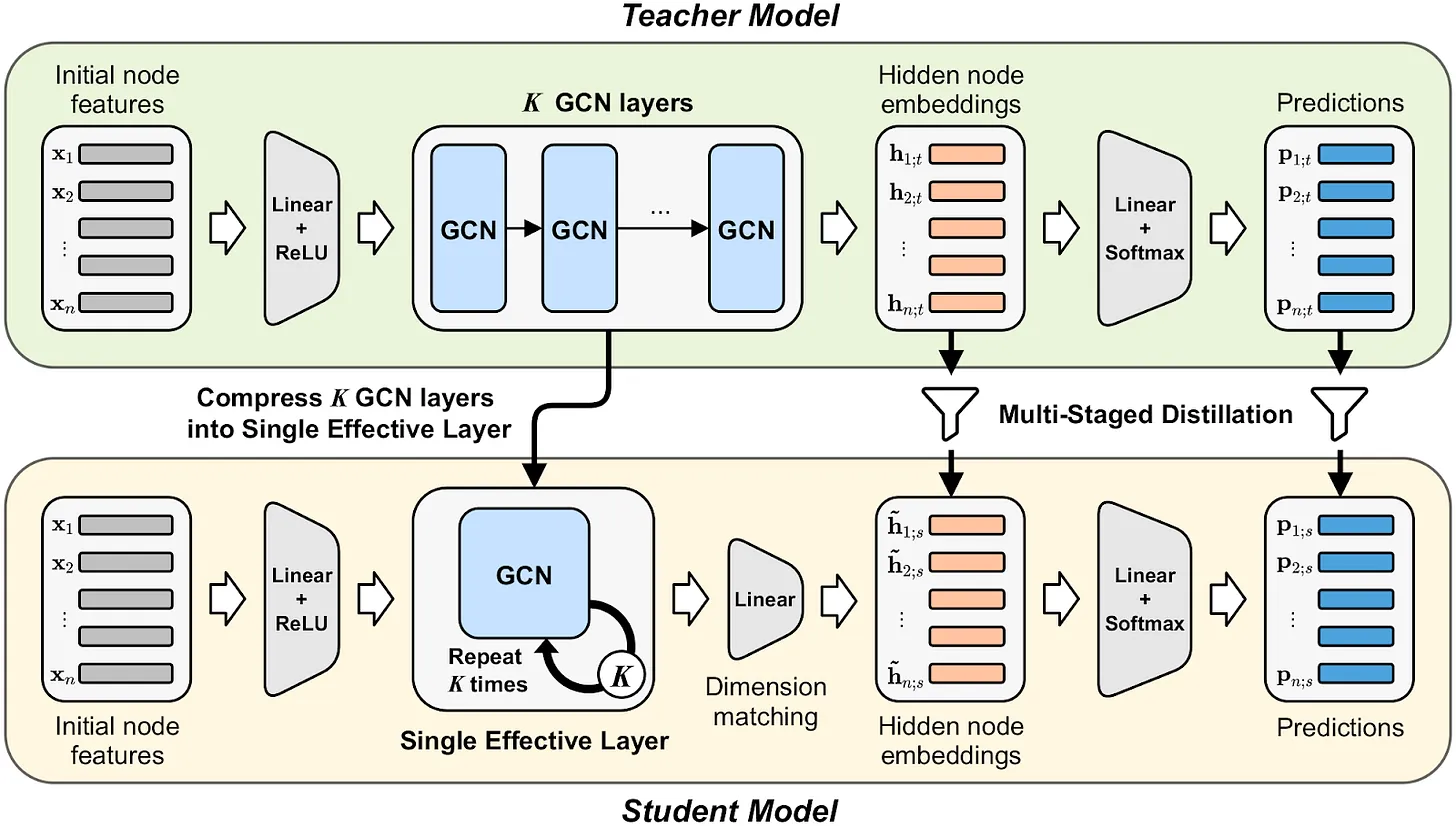
Traditional distillation process | Source: Compressing deep graph convolution network with multi-staged knowledge distillation
The key components of this process are:
- 1
Teacher model
Generates "soft" probability distributions over its output vocabulary using a temperature-scaled softmax function. This allows the teacher to express their confidence in different possible outputs. - 2
Student model
Learns from the teacher’s soft probabilities and the actual "hard" labels, balancing imitation and correctness. - 3
Distillation loss function
Combines cross-entropy loss (encouraging correct predictions) and KL divergence (penalizing deviation from the teacher's probabilities). The loss is defined as:
Where α controls the balance between the two terms L_CE and L_KL.
Keep in mind that the L_CE is the cross-entropy loss between what the student model predicts again the ground truth.
On the other hand, the L_KL is the divergence between the student model's probability distribution p_s and the teacher model's probability distribution p_t
Techniques such as the:
- Smoothed knowledge distillation enhances this method by softening the teacher’s probability outputs. This inherently reduces hallucinations and improves factual consistency. This is especially important for question-answering and fact-based dialogues.
- Task-aware intermediate distillation (TAID) adaptively interpolates between teacher and student representations during training, preventing mode collapse and promoting robust transfer.
This is how we perform knowledge distillation in traditional models. Now, let's understand what distillation in LLM is.
1.2 LLM distillation
Knowledge distillation in the context of LLM takes on fascinating new dimensions. While traditional distillation focuses on classification tasks, LLM distillation must preserve complex reasoning capabilities across diverse contexts. This requires sophisticated approaches that go beyond simple teacher-student knowledge transfer.
The TAID framework is at the heart of modern LLM distillation. Through dynamic temperature scaling, this innovative approach prevents the common pitfall of mode collapse—where student models gravitate toward oversimplified patterns.
By adaptively adjusting the interpolation between teacher and student predictions, TAID maintains the rich, nuanced behaviors of the teacher model while allowing the student to develop its efficient representations.
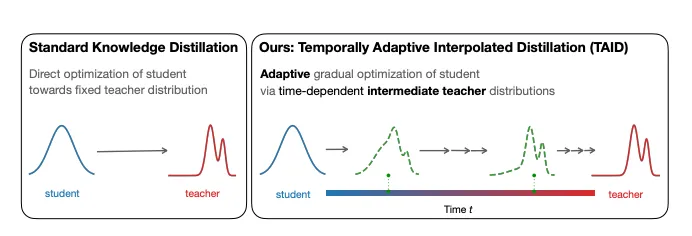
Difference in standard knowledge distillation and TAID | Source: TAID: Temporally adaptive interpolated distillation for efficient knowledge transfer in language models
The temperature parameter is embedded in the probability distribution formula of the teacher and student model,
When τ > 1, the softmax distribution of teacher outputs becomes smoother, revealing subtle relationships between different reasoning paths that might be obscured in sharper distributions. This is particularly important for preserving multi-step reasoning capabilities, where each step builds upon previous insights. Think of it as teaching a student not just the "what" but the "how" of problem-solving.
The benefits of this approach are substantial:
- A 37% reduction in hallucination rates through smoothed knowledge transfer
- Preserved reasoning capabilities with reduced computational costs
- Enhanced generalization across diverse problem domains
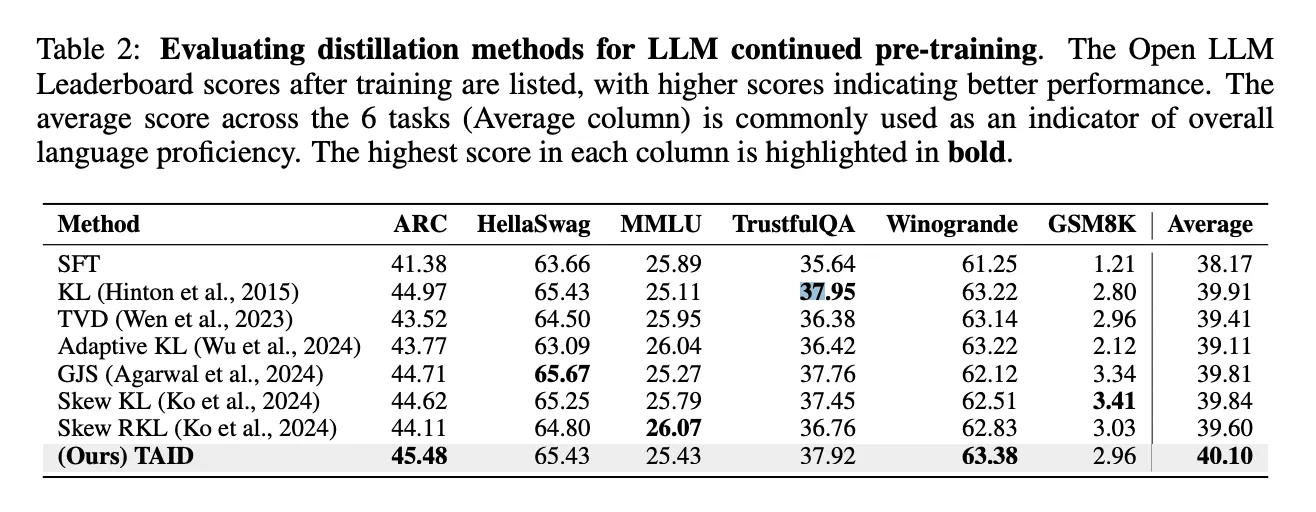
For practitioners implementing LLM distillation, temperature tuning becomes a critical skill.
Setting τ < 1 creates sharp probability distributions that can make student models overconfident in their predictions. Conversely, τ > 1 produces softer distributions that better capture the nuanced relationships between different reasoning paths.
This means that when the temperature is closer to one, the range of search narrows down, and when the temperature of farther away from one, the search area widens.
This is especially important when distilling models for tasks requiring multi-step logical inference or complex problem decomposition.
The loss function balances these competing objectives:
The α parameter allows fine-tuning of this balance, with empirical results suggesting optimal values between 0.3 and 0.7 depending on the specific task and model architectures involved.
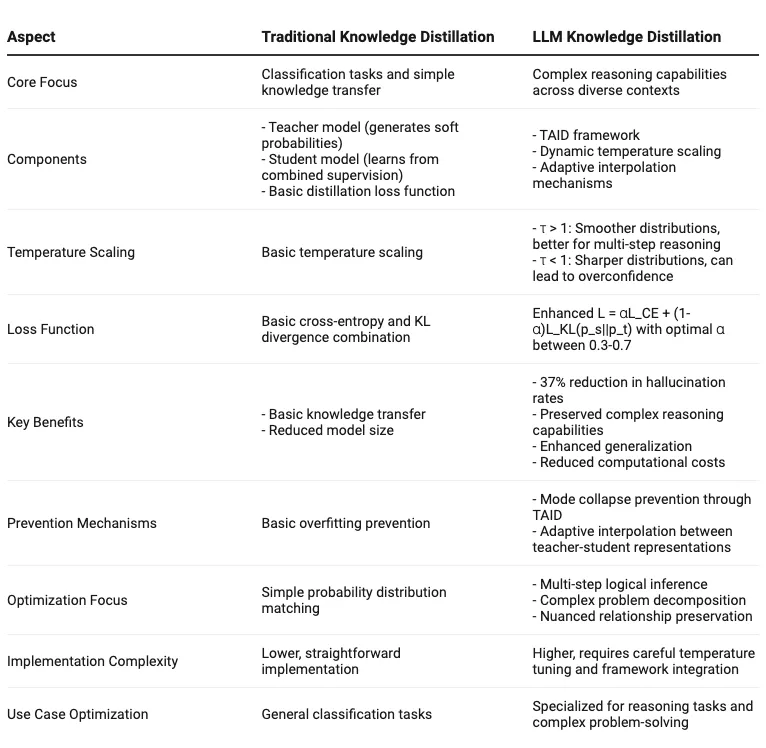
1.3 Comparison table
Below, I have created a comparison table between traditional knowledge distillation and LLM knowledge distillation.
2. Empowering reasoning
In late 2024 and early 2025, we have seen two primary techniques pushing the development of reasoning LLMs: chain-of-thoughts and reinforcement learning. In this section, we will discuss these techniques from the context of model distillation.
2.1 Chain-of-Thought Methods
Imagine solving a complex math problem without breaking it into steps—that's the challenge language models face without Chain-of-Thought (CoT) reasoning. Just as humans benefit from showing their work, LLMs achieve significantly better results when they articulate their reasoning process step by step. The evolution of CoT methods reveals a fascinating progression in how we enable machines to think more systematically.
Zero-shot CoT represents the most basic form, where models are simply prompted to explain their thinking without examples.
Despite its simplicity, this approach yields impressive results, boosting performance on the challenging GSM8K mathematics benchmark by 10.4% to 40.7%. This improvement comes from encouraging the model to decompose problems into manageable steps, like a student learning to show their work.

Comparison of Few-shot-CoT and Zero-shot-CoT | Source: Large language models are zero-shot reasoners
Few-Shot CoT furthers this concept by providing carefully crafted examples demonstrating effective reasoning patterns. When models see how similar problems can be broken down and solved methodically, they learn to apply these patterns to new challenges. The impact is substantial—a 22% improvement on the MATH dataset, which covers a wide range of mathematical problems from basic arithmetic to advanced calculus.
Auto-CoT represents the cutting edge of reasoning enhancement, using sophisticated clustering techniques to select the most relevant examples for any given problem automatically. This dynamic approach improves QA accuracy by 9% while reducing the manual effort needed to create effective prompts. Think of it as an intelligent tutor who knows which examples will best help a student grasp a new concept.
2.2 Symbolic Chain-of-Thought distillation
CoT is a useful tool, but how can we apply it to distill knowledge? I reckon the principle remains the same, teach the student model to learn the reasoning process.
The authors in the paper titled "Symbolic Chain-of-Thought Distillation: small models can also "think" step-by-step" presented a method that enables smaller language models to learn step-by-step reasoning capabilities from larger models.

An illustration of how SCoTD works | Source: Symbolic Chain-of-Thought Distillation: Small models can also “think” step-by-step
The authors propose a technique where a smaller student model is trained on rationalization samples from a much larger teacher model, allowing it to develop CoT reasoning abilities previously only seen in models with >50B parameters.
2.2.1 How does it work?
The process works through several key steps:
Initial setup
- Teacher Model: Large language model (e.g., GPT-3 175B)
- Student Model: Smaller model (e.g., OPT 125M-1.3B)
- Training Data: Set of unlabeled input instances DTrain = {(xi)}
Sampling process
For each input xi in DTrain:
- 1Sample N chain-of-thoughts z̃i with predictions ỹi from teacher
- 2Formula: (ỹᵏᵢ, z̃ᵏᵢ) ~N T(yi, zi|xi,P)
- 3Typically N = 30 samples per instance
Training process
- Create corpus C = {(xi, {(ỹᵏᵢ, z̃ᵏᵢ)}ᴺᵏ₌₁)}
- Train the student using the language modeling loss
- Maximize E(x,ỹ,z̃)~C[S(ỹ,z̃|x)]
Evaluation options
- Greedy decoding: z̃test, ỹtest = argmaxz,y S(z,y|xtest)
- Self-consistency: ỹtest = argmaxy Ez~S(z|xtest)S(y|z,xtest)
2.2.2 Performance Metrics
Default performance comparison
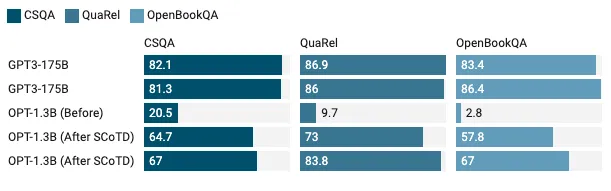
Training data impact
Key achievements:
- 77% latency reduction (23ms vs 100ms baseline)
- 90% parameter reduction while maintaining reasoning capability
- Successful transfer to unseen tasks (79.6% on SST-2)
These results demonstrate that SCoTD successfully enables smaller models to perform complex reasoning tasks previously only possible with much larger models.
2.3 RL-Enhanced distillation
RL-enhanced distillation extends traditional knowledge distillation by incorporating RL signals to guide student model training. The teacher model provides output probabilities and rewards that help shape the student’s behavior. This approach enables smaller models to develop sophisticated reasoning capabilities previously only seen in much larger architectures.
DeepSeek’s implementation
DeepSeek demonstrated two key approaches:
- 1Direct RL distillation through DeepSeek-R1-Zero, achieving 71.0% on AIME 2024 without supervised fine-tuning
- 2Hybrid approach with DeepSeek-R1, combining cold-start data with iterative RL fine-tuning, reaching 79.8% on AIME 2024
Performance comparison
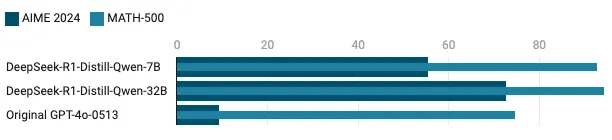
The results demonstrate that distilled models significantly outperform baseline architectures while using far fewer parameters, with DeepSeek-R1-Distill-Qwen-32B achieving performance comparable to much larger models.
3. Benefits of knowledge distillation in language models
Let's discuss the benefits and limitations of knowledge distillation.
3.1 Benefits of knowledge distillation
Here are some benefits of KD:
Computational efficiency
- Model compression achieves 90% parameter reduction while preserving core reasoning capabilities
- Inference latency drops dramatically (23ms/token vs 100ms baseline)
- Significant reduction in storage requirements and energy consumption during deployment
Performance improvements
- Smoothed knowledge distillation reduces hallucination rates by 37%
- Task-aware intermediate distillation (TAID) prevents mode collapse through adaptive interpolation
- Enhanced generalization across diverse problem domains
Practical applications
- Real-time processing enables deployment on edge devices and mobile platforms
- Broader accessibility through reduced infrastructure requirements
- Cost-effective scaling for production environments
3.2 Limitations and Challenges
Now, let's discuss the limitations and challenges of KD.
Technical constraints
- Performance gap remains in highly complex reasoning tasks compared to larger models
- Training process requires significant expertise in temperature tuning and loss function balancing
- Optimal distillation parameters vary by task, making standardization difficult
Implementation challenges
- Initial setup costs for teacher model training and data preparation can be substantial
- Real-time monitoring and quality assurance require specialized tooling
- Model updates need careful validation to maintain performance across all use cases
Business considerations
- Not all applications benefit equally from distillation—some tasks still require full-scale models
- Resource requirements for initial training may offset short-term cost benefits
- Team expertise needs may increase during the implementation and maintenance phases
4. Implementing knowledge distillation in LM
In this section, we will discuss some of the frameworks for KD as well as walk through Nvidia's implementation of KD in LLM.
4.1. Frameworks for knowledge distillation in LLMs
Leading frameworks for implementing knowledge distillation in language models offer robust capabilities for model compression and performance optimization:
Available frameworks
- 1Hugging Face Transformers: The Distiller class provides streamlined knowledge transfer between teacher and student models, with built-in support for various distillation techniques and optimization methods.
- 2Nvidia Nemo: It offers a wide range of services for building GenAI models. It is a cloud to develop and deploy your models. Apart from model distillation you can also prune the models.
- 3TensorFlow Model Optimization: Offers comprehensive tools for model pruning, quantization, and distillation, ideal for production deployments.
- 4PyTorch: Specializes in deep learning model compression with extensive utilities for managing the distillation process and optimizing model efficiency.
- 5DeepSpeed: Microsoft’s optimization library includes advanced features for model distillation, particularly suited for large-scale deployments.
4.2 How to implement KD for LLM
In this section, I will show you how to implement KD using the Nvidia Nemo framework. The team from Nvidia has already implemented the tutorial, I am just using the repo to guide you and show you how simple it is to implement KD.
You can find the full tutorial here.
NeMo installation
- For the installation guide to this repo here and use the following command to install NeMo
Data Preparation
- Curate a representative dataset that covers target tasks like the WikiText-103-v1 dataset.
- Implement data augmentation for improved generalization
- Ensure proper validation split for monitoring distillation quality
How to prepare the dataset | Source: LLM Model Pruning and Knowledge Distillation with NVIDIA NeMo Framework
Teacher Model Selection and fine-tuning
- Choose a well-performing pre-trained model like the Meta-Llama-3.1-8B.
- Fine-tune the model on the prepared dataset
Bash command to fine-tune the teacher model | Source: LLM Model Pruning and Knowledge Distillation with NVIDIA NeMo Framework
Model distillation
- Initialize student model architecture
- Configure hyperparameters (learning rate, batch size)
Bash command to train the student model | Source: LLM Model Pruning and Knowledge Distillation with NVIDIA NeMo Framework
Evaluation and Optimization
- Monitor accuracy metrics
- Measure inference speed improvements
Bash command to visualize the model’s performance | Source: LLM Model Pruning and Knowledge Distillation with NVIDIA NeMo Framework
5. Real-world applications
Here are some business applications for PMs, AI engineers, and startup folks.
For Product Managers
- Chatbots and virtual assistants that deliver enterprise-grade performance at consumer-scale costs
- Real-time NLP tools for customer service with 77% lower latency
- Mobile-first AI applications previously constrained by model size
For AI Engineers
- Efficient deployment of reasoning capabilities across edge devices and cloud infrastructure
- Streamlined model updates and maintenance through reduced computational requirements
- Integration flexibility with existing tech stacks due to smaller model footprints

Source: Sam Altman on X
For Startup leadership
- Faster go-to-market with reduced infrastructure investment
- Competitive advantage through advanced AI capabilities at lower operational costs
- Scalable solution that grows efficiently with user demand
Performance Metrics From Real-World Implementation
Conclusion
Knowledge distillation represents a transformative approach to making large language models more accessible and deployable across diverse environments. This comprehensive exploration demonstrates how organizations can achieve up to 90% parameter reduction while maintaining core model capabilities, revolutionizing the practical implementation of AI systems.
Key section learnings
- Foundations: Knowledge distillation leverages temperature-scaled softmax and specialized loss functions to transfer knowledge effectively between teacher and student models
- Implementation: Modern frameworks like Hugging Face and NVIDIA NeMo provide robust tooling for distillation, with clear pathways for deployment
- Performance: Success stories like DeepSeek show dramatic improvements (77% latency reduction, 37% fewer hallucinations) while maintaining model capabilities
- Applications: Real-world implementations demonstrate effectiveness across chatbots, edge computing, and enterprise systems
Stakeholder opportunities
- Product Managers can leverage distilled models for cost-effective, real-time applications
- Engineers benefit from simplified deployment and maintenance processes
- Leadership teams can accelerate AI adoption while managing resource constraints
Future considerations
As we advance in AI deployment, a crucial question emerges: How will knowledge distillation evolve to balance the increasing capabilities of foundation models with the practical constraints of real-world applications? This balance between power and practicality will likely shape the next generation of AI implementations.
References
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12