Introduction
In large language models (LLMs) attention mechanism remains one of the most important components since its release in 2014 by Graves et.al. It essentially tell the model to focus and pay attention to the important information in the given data.
Attention in AI is about focus.
Think of how your mind zeroes in on important information when you’re learning something new. For instance, when you read a book, not every word carries equal weight, right? Your brain naturally picks out the key parts while the less important details fade into the background.
AI systems now work in a similar way. When processing a sentence like "A nice cup of hot coffee really make my day," these systems identify connections between words. They recognize that "hot" relates to "coffee" rather than to other words in the sentence.
Now, for example, if we were to understand how these relationships look, we could use a heatmap to visualize the attention score.
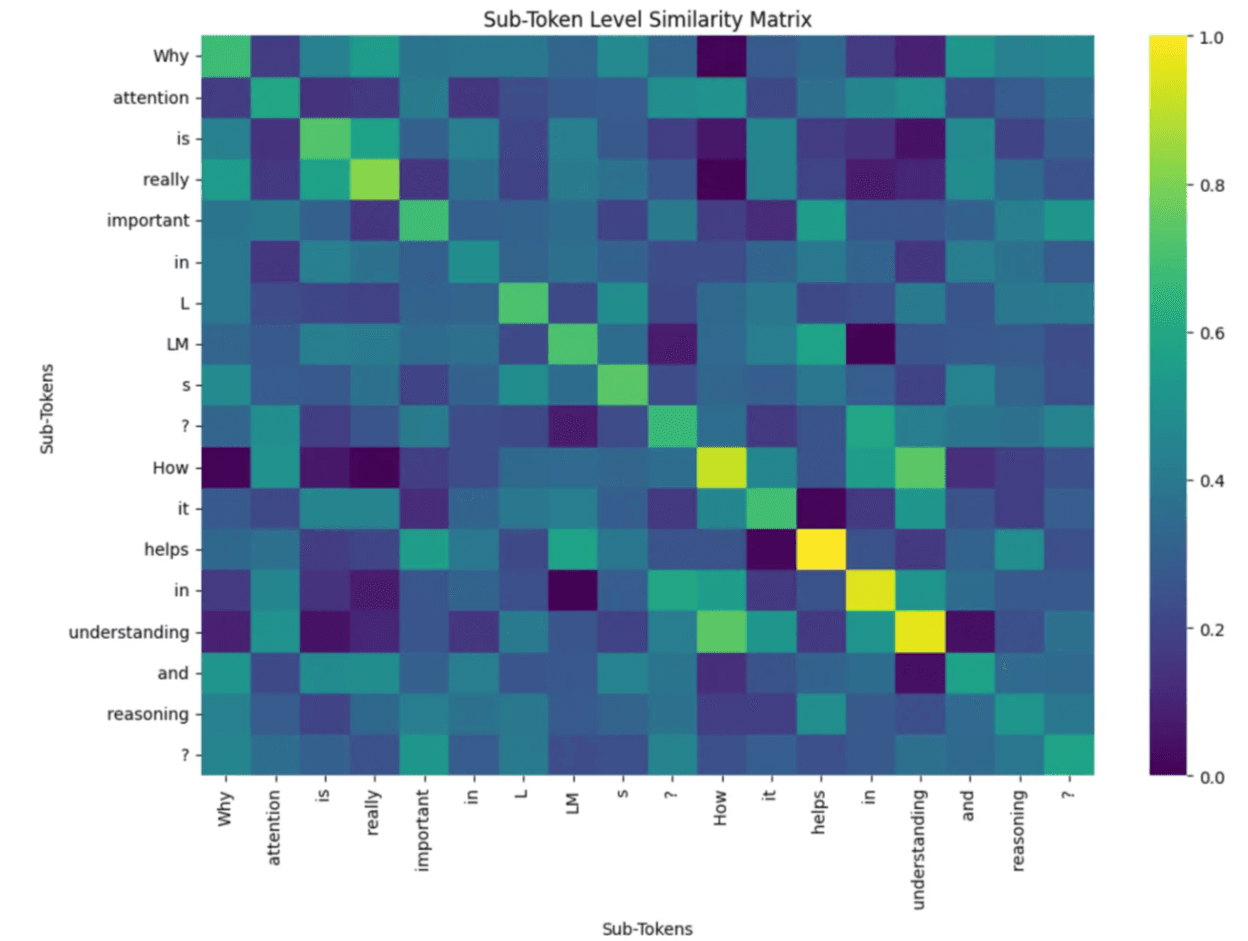
Source: A study on Attention mechanism
This image shows a “Sub-Token Level Similarity Matrix” heatmap that reveals how words relate to each other in AI language models.
The colors indicate how strongly words connect - bright yellow shows the strongest connections (1.0), while dark purple shows the weakest (0.0).
Certain pairs of words have bright spots, especially along sequences like "How it helps in understanding." These yellow and green squares show which words the AI model sees as closely related.
This visualization helps us understand how AI models like large language models actually “pay attention" to relationships between different words when processing text, similar to how humans understand that "hot" relates to "coffee" in a sentence.
Earlier, AI had trouble with lengthy text because it processed information sequentially, often losing track of earlier content. This changed in 2017 when researchers developed Transformers, which made attention the centerpiece of their design.
Unlike previous approaches, Transformers examine all words simultaneously, understanding how each relates to others. This improvement helps today’s AI grasp context more naturally and respond with greater relevance.
That’s why modern AI can hold meaningful conversations and provide helpful responses - it's paying attention to what truly matters in your message.
Let’s understand a little more about the theory and the variety of attention mechanisms.
Theoretical Foundations and Mathematical Formulations
Attention mechanisms form the core of modern LLMs. They enable models to focus on relevant information when processing sequences. Let’s explore how they work in simple terms.
Historical Evolution
Attention first appeared in 2014 by Graves et al., as an improvement to sequence models. But it received much traction in 2015. It was when Bahdanau and his team released their additive attention mechanism. This attention allowed machine translation models to focus on different parts of the input sentence while generating each word. This additive attention helped solve the bottleneck problem in sequence-to-sequence models by letting the decoder directly access all states from the encoder.

This picture shows how additive attention works in language models. At the bottom, we see the encoder reading input words one by one. The red box in the middle is the attention layer. It helps the model focus on important words. The attention layer gives each input word a score called α. Words with higher scores get more attention. The blue box at the top is the decoder. It uses these attention scores to create better translations. This method helps the model remember long sentences better. Before this, models would forget parts of long sentences | Source: Attention? Attention!
In the years between, various other attention mechanisms were released. See the table below.
But in 2017, the groundbreaking "Attention Is All You Need" paper introduced transformers that rely entirely on attention mechanisms. Vaswani et. al., 2017 approach took this idea even further by making attention the only core building block of the Transformer architecture, completely removing recurrence and using self-attention to let each word in a sequence directly connect with every other word.This approach revolutionized natural language processing by enabling parallel processing and better handling of long-range dependencies.
Attention allows models to weigh the importance of different input elements. Unlike previous sequential approaches, transformers use attention to process all parts of the input simultaneously, making them more efficient on modern hardware.
Mathematical Formulation
At its core, attention uses three key components:
- Queries (Q): What we're looking for
- Keys (K): What we match against
- Values (V): The information we want to gather
The basic attention operation follows this formula:
Where:
- Q, K, and V are matrices representing queries, keys, and values
- d_k is the dimension of the key vectors
- Softmax turns raw scores into probability distributions
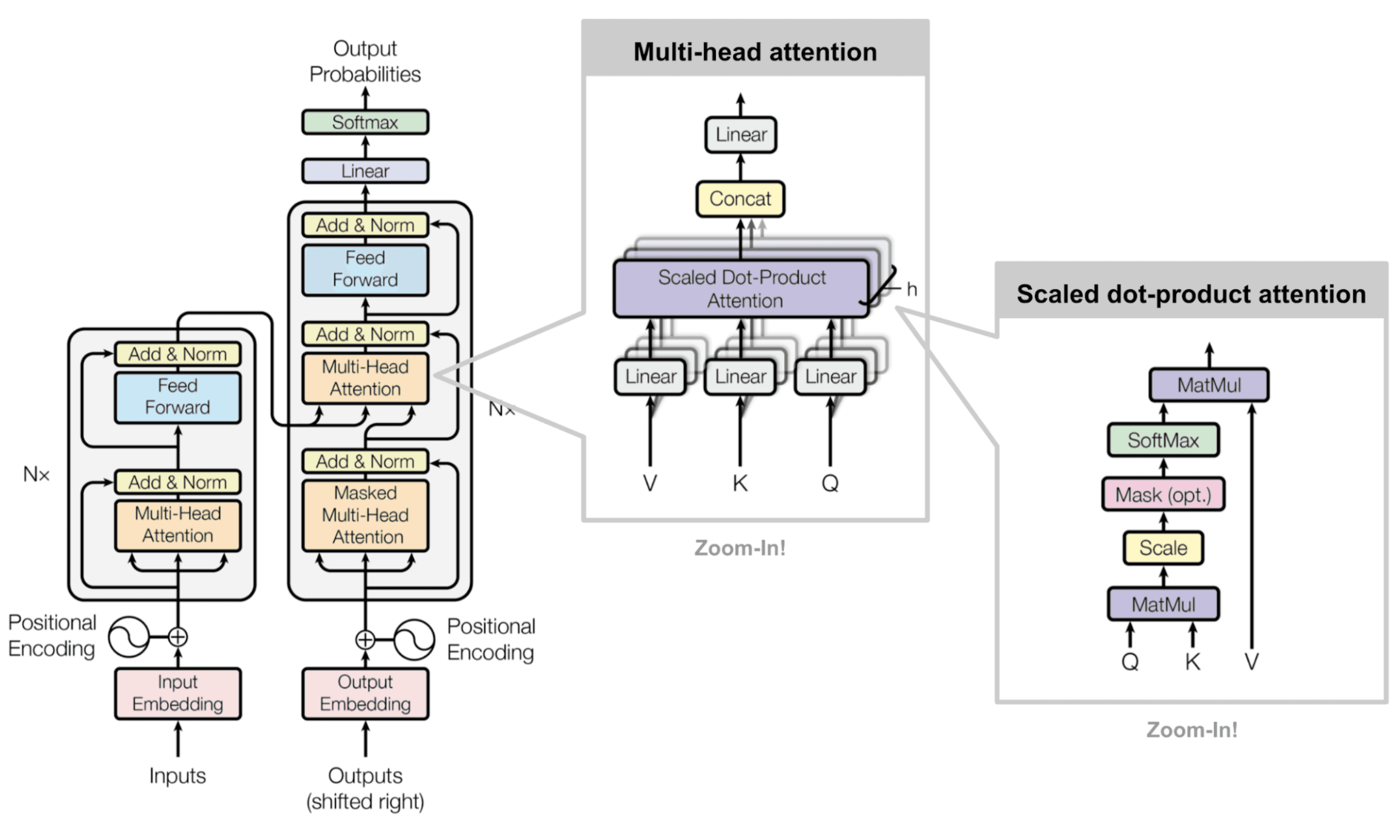
The transformer architecture predominantly uses the attention mechanism. | Source: Attention? Attention!
This diagram shows the Transformer model from the "Attention Is All You Need" paper. The left side shows the complete model with input and output paths. The middle box zooms in on multi-head attention. The right box explains scaled dot-product attention in detail.
In the right box, we see how attention works with Q (Queries), K (Keys), and V (Values). The model multiplies Q and K, scales the result, applies a mask if needed, uses softmax to create attention weights, and multiplies by V to get the final output.
Multi-head attention (middle box) runs this process multiple times in parallel. Each head focuses on different parts of the input. The results from all heads are combined (concatenated) and processed through a final linear layer.
This approach lets the model process all words at once instead of one by one. It helps the model understand relationships between words even when they're far apart in a sentence.
Key Attention Variants
In this section, we will discuss the five most basic and widely known attention variants.
Self-attention mechanism
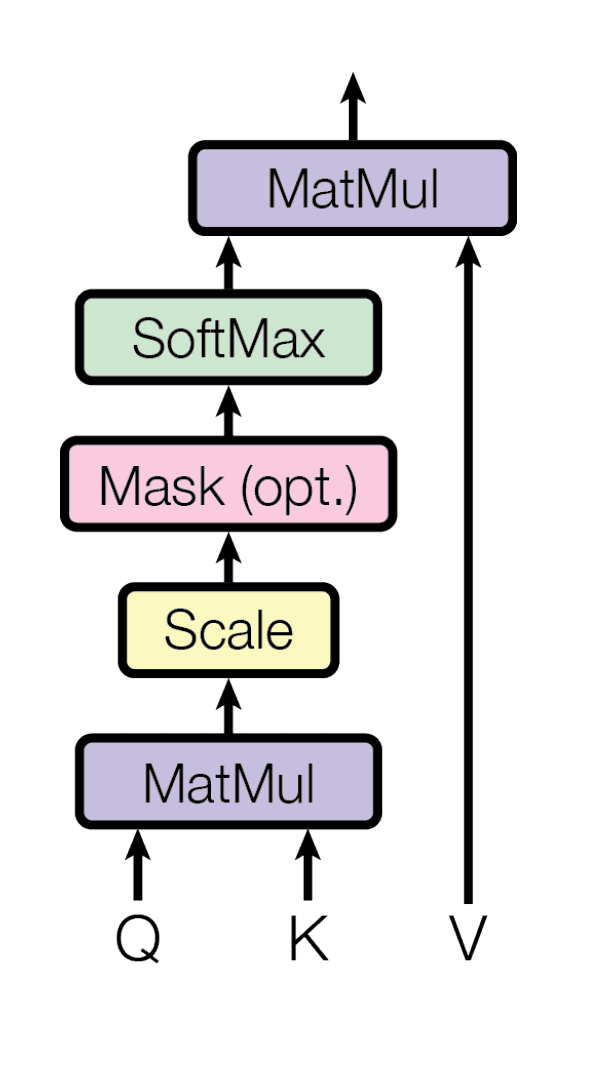
Self-attention diagram | Source: Attention Is All You Need
Self-attention is like reading a sentence. Essentially, it is understanding how each word relates to others. When the model processes "The cat sat on the mat," it connects "cat" with "sat" to understand who's doing the sitting. This helps models grasp the context within prompts. In prompt engineering, well-structured prompts help self-attention create stronger connections between important elements.
The self-attention operation can be expressed mathematically as:
Where Q, K, and V are query, key, and value matrices derived from the input sequence.
Multi-head attention mechanism

Multi-head attention diagram | Source: Attention Is All You Need
Multi-head attention works like having multiple readers, each focusing on different aspects of the text. One head might focus on subject-verb relationships, another on emotional tone, and yet another on factual details. The model combines these perspectives for a complete understanding. This is why prompt engineering strategies often include multiple aspects (instructions, examples, context) that different attention heads can process in parallel.
Multi-head attention is calculated as:
Where each head is computing attention separately:
Flash Attention
Flash Attention revolutionized LLM efficiency by changing how attention is calculated. It processes attention in smaller blocks, dramatically reducing memory requirements without changing results. This optimization allows models to handle much longer prompts without running out of memory.
Flash Attention maintains the same mathematical formulation but uses a block-based computation:
For prompt engineers, Flash Attention enables working with detailed contexts and examples that wouldn't fit in earlier models.

Standard attention vs Flash attention | Source: Flash Attention
This image compares traditional attention and Flash Attention in large language models:
On the left: Standard Attention Implementation shows multiple memory transfers between HBM (High-Bandwidth Memory) and compute units. It loads Q and K matrices, writes S, loads S, writes P, loads P and V, and finally writes O, requiring many back-and-forth memory operations.
On the right: Flash Attention reduces these transfers by loading data in blocks (Kj, Vj and Qi, Oi, li, mi) and fusing operations together. Instead of writing intermediate results back to memory, it keeps them in fast on-chip memory and processes them in smaller chunks.
The key advantage is that Flash Attention calculates the same results but with fewer memory transfers. It divides matrices into blocks to work within SRAM memory limits, processing row by row, column by column. This makes models faster and able to handle longer texts without running out of memory.
Sparse Attention
Sparse Attention focuses only on important connections rather than considering every possible token pair. Models like Longformer and BigBird use this approach to handle documents with 100,000+ tokens. They combine local patterns (looking at nearby words) with global tokens that connect to everything. This pattern works well for prompt engineering techniques that involve long reference materials or detailed instructions.
The sparse attention pattern can be represented as:
Where M is a mask that zeroes out positions we don't want to attend to.

Illustration of how Sparse Attention works. | Source: Sparser is Faster and Less is More: Efficient Sparse Attention for Long-Range Transformers
This image shows how Sparse Attention works in language models:
On the left: A grid displays which tokens pay attention to others. Darker squares (1's) show strong connections, while lighter squares (0's) show ignored connections. Not every token connects to every other token, creating a "sparse" pattern.
On the right: A flowchart shows how Sparse Attention filters connections. Input states go through a selection process where:
- 1An importance score (u) determines which connections matter
- 2A threshold function τ(u) creates a mask (M)
- 3Only the important connections pass through to the attention calculation
The key benefit is that by focusing on only important connections, the model can process much longer documents (100,000+ tokens) while using less memory and computing power. It's like having a conversation where you only focus on the most relevant parts of what was previously said, rather than equally weighing every word.
Grouped-Query Attention
Grouped-Query Attention (GQA) balances efficiency and quality by having groups of query heads share key-value pairs. It provides much of the speed benefit of Multi-Query Attention while maintaining better output quality. This mechanism powers many modern LLMs, enabling them to respond more quickly to complex prompts without sacrificing an understanding of nuanced instructions.
GQA can be calculated as following:
Where each head is computing attention separately:

Overview of Multi-head, Group-Query, and Multi-Query Attention. | Source: GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
This image compares three types of attention mechanisms used in language models:
On the left: Multi-head attention shows each query (blue) having its own matching key (pink) and value (yellow) - like 8 separate lookups working independently.
In the middle: Grouped-query attention (GQA) shows queries grouped together (2 queries sharing each key-value pair) - a balanced approach that saves memory while maintaining good performance.
On the right: Multi-query attention shows all queries sharing just one key and value - the most efficient but potentially less accurate approach.
The grouped query approach (middle) represents a practical compromise: it processes information faster than having separate heads for everything, but maintains better understanding than the fully shared approach. This helps modern AI models respond quickly while still understanding complex instructions.
Additionally, below is the list of other attention mechanisms with alignment score functions and key features.
Understanding these variants helps create prompts that work with rather than against the model's attention mechanisms, resulting in more predictable and effective outputs.
Memory Consumption and Computational Efficiency Analysis
One of the biggest challenges with attention mechanisms is their computational cost. Let's break down how different attention types use memory and processing power.
Memory Footprint Evaluation
Standard attention requires comparing every token with every other token. This creates what we call "quadratic complexity" - written as O(n²). In simple terms:
- If you double your text length, you need four times the memory
- A 1024-token sequence needs about 4MB of memory (FP16)
- A 4096-token sequence might need ~64MB just for attention
The memory usage formula for standard attention is:
Memory ≈ n² × d (for attention maps) + n × d × h (for KV cache)
Where:
- n is sequence length
- d is dimension size
- h is number of heads
Efficiency Metrics
Different attention variants offer trade-offs between accuracy and efficiency:
Practical Implications
The choice of attention mechanism impacts what you can do with your model:
- 1Standard attention works well for shorter texts (up to 2K tokens)
- 2Memory-efficient attention (FlashAttention) extends this to 8-16K tokens
- 3Sparse patterns like sliding windows can handle 100K+ tokens
- 4Group query attention speeds up generation without major quality loss
Modern LLMs typically combine several of these techniques to balance memory usage, speed, and accuracy for different situations.
Comparative Performance Analysis in Contemporary LLMs
How do different attention mechanisms affect real-world LLM performance? Let's examine how various models implement attention and the results they achieve.
Benchmarking Across Models
Modern LLMs use different attention techniques to achieve their capabilities:
Performance Trade-offs
Different attention mechanisms create distinct advantages:
Throughput vs. Sequence Length
- Standard attention: Rapid dropoff in throughput as sequence grows
- FlashAttention: Maintains higher throughput (3-4× faster at 8K tokens)
- GQA/MQA: Nearly doubles decoding speed by reducing memory bandwidth
Memory Usage vs. Context Length
- Standard attention (16 heads): ~2GB for 4K tokens
- Multi-query attention: ~0.2GB for the same sequence
- Claude-style sparse attention: Linear scaling to 100K tokens
Accuracy vs. Efficiency
- Full softmax attention: Best quality but most resource-intensive
- Linear attention: Much faster but lower quality for language tasks
- Sparse patterns: Good middle ground for long documents
Key Insights
The choice of attention mechanism directly influences what models excel at:
- o3 and similar models allocate more computation for reasoning tasks
- Claude models optimize for extremely long documents
- DeepSeek models use attention sparsity for efficiency
- Consumer-facing models use MQA/GQA for faster responses
The most capable systems combine multiple attention techniques, tailoring them to specific use cases.
Conclusion
Attention mechanisms remain the backbone of modern LLMs. Their evolution has transformed how AI processes information. Here’s what we’ve learned:
- 1Attention helps LLMs focus on what matters in the text, similar to human reading.
- 2It evolved from simple mechanisms to sophisticated variants like self-attention and multi-head attention.
- 3Different types serve different purposes - some optimize for speed, others for memory efficiency.
The trade-offs are clear:
- Standard attention offers quality but consumes memory.
- Flash Attention reduces memory needs without sacrificing results.
- Sparse Attention handles extremely long texts efficiently.
- Group-Query Attention or Multi-Query Attention speeds up response generation.
Leading models combine multiple attention types to balance performance needs. The GPT-4 series emphasizes reasoning quality. Claude excels with long documents through sparse patterns. DeepSeek maximizes efficiency with parameter sharing.
As LLMs continue to develop, attention mechanisms will evolve further, enabling more powerful and efficient AI systems.