
GPU technology stands at the core of effective LLM deployment, yet many teams struggle to optimize their inference setups. The gap between theoretical performance and actual results often stems from misunderstanding the unique hardware demands of inference workloads. This guide unpacks the essential GPU concepts that directly impact your model serving efficiency and cost structure.
We'll examine how modern GPU architectures handle the matrix operations central to transformer models, with particular focus on memory bandwidth limitations during token generation. You'll learn why the Roofline Model matters for predicting performance bottlenecks and how specialized techniques like KV-caching and quantization can dramatically improve your inference metrics.
This knowledge translates to immediate benefits: reduced inference costs, improved response times, and more efficient resource utilization. Armed with these insights, you can make strategic decisions about hardware selection, batching configurations, and optimization techniques.
Key Topics Covered:
- 1GPU architecture fundamentals for LLM workloads
- 2Training versus inference hardware requirements
- 3Memory management through KV-caching and optimization
- 4Evolution of specialized inference architectures
- 5Precision trade-offs in quantization techniques
- 6Framework selection and batching strategies
GPU fundamentals for LLM inference
Let's begin by exploring the essential components and principles that make GPUs particularly well-suited for LLM inference workloads.
Architecture of modern GPUs for LLM workloads
Modern GPUs are designed with specialized components crucial for LLM inference. The processing engines, known as Streaming Multiprocessors (SMs), contain tensor cores specifically engineered for matrix-multiply-accumulate operations. These cores enable massively parallel matrix operations, providing significant speedup over standard floating-point units. High-end GPUs also feature transformer engines that analyze each layer of a transformer model and automatically select optimal precision formats for activations.

The basic architecture of a GPU consists of multiple SM. | Source: Streaming Multiprocessor (SM)
Memory hierarchy plays a vital role in GPU performance during inference. The high-bandwidth memory (HBM) serves as the main storage for model weights, while faster on-chip SRAM caches intermediate results. This hierarchy creates a tradeoff between capacity and speed that directly impacts inference performance.

Memory hierarchy | Source: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
A single inference step requires loading billions of parameters into compute units, making efficient memory access patterns critical for overall system performance.
Matrix operations in transformer models
Transformer models rely heavily on matrix operations, particularly during attention mechanisms and feed-forward networks. During inference, these operations must be computed efficiently to minimize latency.
Key Components:
- For each input token, the GPU computes key-value pairs that are cached for subsequent token generation
- This KV cache represents a significant portion of memory usage during inference
- The model then performs matrix multiplications between these cached values and new query vectors to generate the next token
GPU tensor cores accelerate these computations by performing hundreds of multiply-accumulate operations in parallel. A single tensor core can execute thousands of floating-point operations per clock cycle when fully utilized.
The Roofline Model for LLM inference
The Roofline Model provides a visual framework for understanding when LLM inference becomes memory-bound versus compute-bound. This model plots achievable performance against operational intensity (operations per byte of memory accessed).

Source: Roofline model
LLM inference has two distinct phases with different computational characteristics:
- 1
Prefill phase
Processes the entire prompt in parallel and is typically compute-bound - 2
Decode phase
Generates tokens sequentially and is usually memory-bound
By calculating the operations-to-byte ratio of your GPU and comparing it to the arithmetic intensity of your model's attention layers, you can determine whether your inference is limited by compute capacity or memory bandwidth.
Example: When running Llama 2 on an A10 GPU, the arithmetic intensity during decode is around 62 operations per byte, while the GPU's peak ops:byte ratio is 208.3. This indicates that inference is memory-bound, meaning improvements in memory bandwidth would yield better performance than more compute capacity.
Memory bandwidth as the critical bottleneck
Memory bandwidth often represents the primary bottleneck for LLM inference rather than raw compute capacity. This is especially true during the decode phase, where each new token generation requires loading the entire model from memory.
When generating text autoregressively, the GPU must load model parameters multiple times, with relatively few computations performed per parameter. The Model Bandwidth Utilization (MBU) metric—defined as achieved memory bandwidth divided by peak memory bandwidth—helps quantify how efficiently the hardware is being utilized.

Strategies to Address Memory Bandwidth Limitations:
- Batching requests to amortize the cost of loading model weights across multiple inference requests
- Choosing GPUs with higher memory bandwidth
- Implementing weight quantization techniques
- Optimizing memory access patterns
For latency-sensitive applications where batching isn't viable, choosing GPUs with higher memory bandwidth or implementing memory optimization techniques like weight quantization becomes essential for performance improvements.
Understanding these GPU fundamentals provides the foundation for effective LLM deployment, highlighting why both hardware selection and optimization techniques must be carefully tailored to inference workloads.
Training vs. Inference: Contrasting Hardware Requirements
When deploying large language models, understanding the distinct hardware demands for training versus inference is crucial for optimal performance and cost efficiency. Let's explore how these workloads differ and what this means for hardware selection.
Compute focus vs. memory bandwidth
Training LLMs is primarily compute-bound, requiring massive parallel processing capabilities to handle large matrix-matrix multiplications. In contrast, inference—especially during the decode phase—is typically memory-bound, with speed limited by how quickly model parameters can be loaded from GPU memory rather than by raw computational power.
The two phases of inference
Inference consists of two distinct phases with different hardware requirements:
Memory requirements that scale with model size
For a 70B parameter model in half-precision, approximately 140GB of memory is needed just to store the weights. Additional memory is required for the growing key-value (KV) cache during token generation. This explains why multiple GPUs are often needed even though their compute capacity may be underutilized.
Hardware optimization priorities
Training systems prioritize:
- Maximum VRAM capacity to hold large models
- High parallel compute capabilities across multiple GPUs
- Robust GPU-to-GPU communication for gradient synchronization
Inference systems prioritize:
- Memory bandwidth for rapid weight loading
- Time-per-output-token efficiency
- Batching capabilities to maximize throughput
Performance metrics and scaling considerations
Inference performance is measured through metrics like Time To First Token (TTFT) and Time Per Output Token (TPOT). While adding more GPUs can reduce latency, the scaling is sub-linear due to communication overhead. For example, doubling from 4 to 8 GPUs for a 70B model typically reduces latency by only 30%, not 50%.
Scaling Considerations:
- 1A single GPU with high bandwidth memory may outperform multiple lower-tier GPUs for latency-sensitive applications
- 2Batching across multiple GPUs can significantly improve throughput for high-volume workloads
- 3Communication overhead increases with additional GPUs
- 4Sub-linear scaling means diminishing returns from adding more hardware
These fundamental differences between training and inference requirements explain why hardware optimized for model training may not be ideal for deployment scenarios, highlighting the need for specialized inference infrastructure.
Memory management techniques: KV-caching and optimization
Memory management is a critical aspect of efficient LLM inference, with KV cache optimization being especially important for high-performance deployment. As models process longer contexts and larger batches, strategic memory optimization becomes essential for sustainable and cost-effective inference. Let's explore the cutting-edge approaches that make efficient LLM serving possible.
Understanding KV cache fundamentals
KV cache stores key and value tensors from previous tokens during generation to avoid redundant computations. When generating new tokens, LLMs rely on these cached values rather than recomputing them. This caching mechanism significantly improves inference speed but introduces memory challenges as sequence length increases.
KV Cache Memory Formula:
Total KV cache size (bytes) = batch_size × sequence_length × 2 × num_layers × hidden_size × precision_in_bytes
For large models with substantial context lengths, KV cache can dominate memory usage. With models like Llama 2 70B and a batch size of 32 at sequence length 1024, the KV cache alone requires approximately 10GB in FP16 precision.
PagedAttention
PagedAttention addresses memory fragmentation by implementing paging techniques inspired by operating systems. Instead of allocating contiguous memory blocks for each request's KV cache, it:
- 1Splits KV cache into fixed-size blocks
- 2Dynamically allocates memory blocks as needed
- 3Maintains a mapping table between logical and physical memory locations
- 4Enables non-contiguous memory storage while preserving efficient attention computation
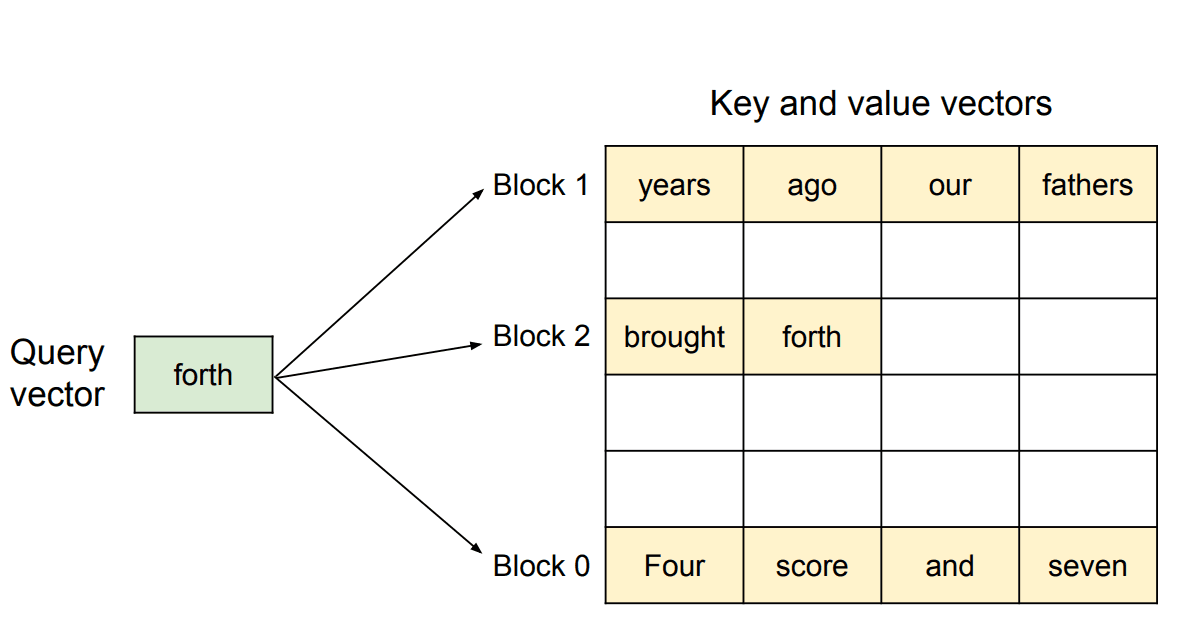
Illustration of PagedAttention's non-contiguous memory management, showing how a query vector accesses relevant key-value tokens across separate memory blocks rather than requiring contiguous allocation. | Source: Efficient Memory Management for Large Language Model Serving with PagedAttention
This approach significantly reduces memory wastage, allowing for 2-4× higher throughput compared to static allocation schemes. PagedAttention effectively limits memory waste to under 4% in most cases.
Practical impact of dynamic allocation
Without PagedAttention, serving systems must pre-allocate maximum-sized buffers (e.g., 2048 tokens) regardless of actual usage. With dynamic allocation, memory is assigned only when needed, substantially improving GPU utilization and enabling higher batch sizes.
Quantization for KV cache
Quantization reduces precision of KV cache values, dramatically decreasing memory requirements:
Memory Reduction Options:
- INT8 KV cache reduces memory usage by 50% compared to FP16
- Lower precision formats like 4-bit and even 2-bit quantization can further reduce memory footprint
- Specialized techniques like ZeroQuant, AWQ, and SqueezeLLM enable 30-70% reduction in memory usage
Recent implementations combine KV cache quantization with weight quantization, enabling significant throughput improvements. For example, INT8 KV cache with AWQ weight quantization shows up to 240% throughput increase at batch size 1.
Flash Attention optimizations
Flash Attention algorithms optimize memory access patterns through:
- IO-aware implementation that accounts for GPU memory hierarchy
- Tiled attention computation to maximize SRAM utilization
- Fused operators that reduce memory overhead during attention calculation
- Optimized softmax reduction that minimizes HBM access
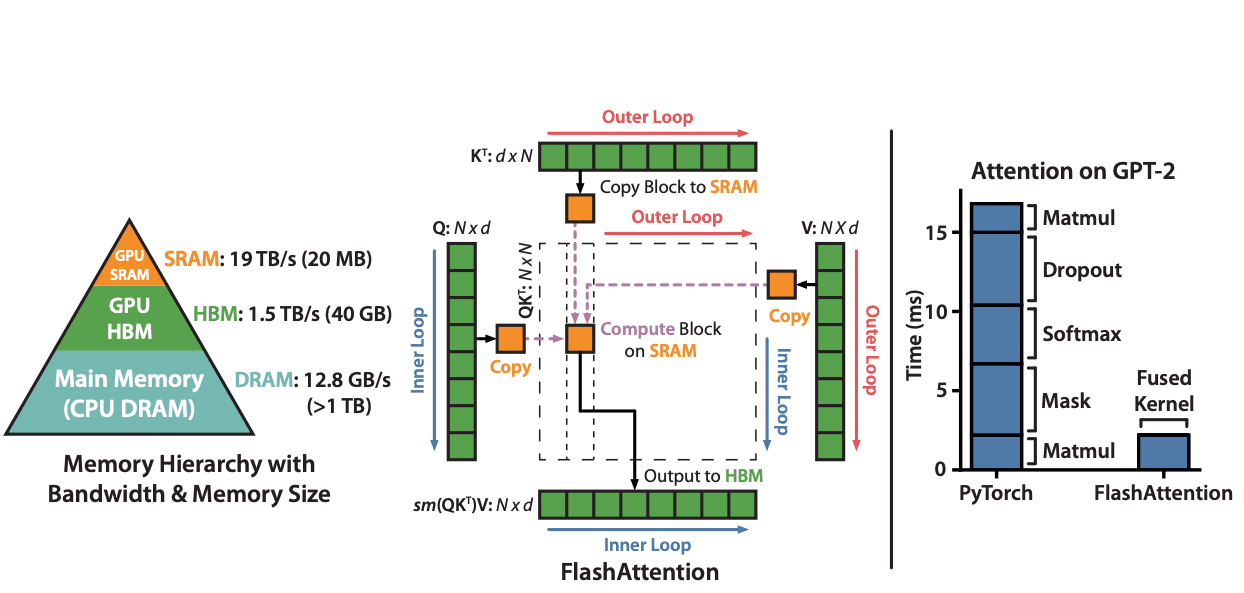
FlashAttention-3, the latest iteration, further enhances performance with asynchronous operations and improved parallel processing. It eliminates the need for padded tensors, significantly reducing VRAM usage for variable-length sequences.
Advanced compression techniques
Recent research has produced specialized methods for KV cache compression:
These techniques enable longer context processing with minimal performance degradation, making previously infeasible context lengths practical on consumer hardware.
Memory optimization remains one of the most active areas of LLM inference research, with new techniques consistently improving efficiency and enabling deployment of increasingly powerful models in resource-constrained environments.
With memory management techniques well established, we now turn our attention to the evolution of GPU architectures specifically designed to address the unique challenges of inference workloads.
GPU architecture evolution for inference workloads
The landscape of GPU technology continues to evolve rapidly, with manufacturers developing specialized architectures that address the unique demands of LLM inference. Let's examine how these advancements are reshaping what's possible in model deployment.
The rise of specialized tensor cores
NVIDIA's Blackwell Ultra Architecture represents the cutting edge in GPU design for LLM inference. This architecture features enhanced tensor cores that deliver twice the attention-layer acceleration and 1.5 times more AI compute FLOPS than previous generations. The Blackwell architecture introduces significant advancements in precision support, enabling efficient FP4 and FP6 calculations critical for modern inference workloads.
Key Advancements:
- Enhanced tensor cores with 2x attention-layer acceleration
- 1.5x more AI compute FLOPS than previous generations
- Support for efficient FP4 and FP6 calculations
- HBM4 ultra-high-bandwidth memory providing up to 2.5 TB/s
Memory bandwidth has historically been a key bottleneck in inference performance. The introduction of HBM4 ultra-high-bandwidth memory addresses this challenge by providing bandwidth up to 2.5 TB/s in solutions like the Vera Rubin SuperChip, which can deliver up to 50 PFLOPS of compute power specifically optimized for FP4 precision AI workloads.
Performance scaling across generations
Benchmark tests demonstrate remarkable improvements in inference capabilities across GPU generations. The latest MLPerf Inference v5.0 benchmarks introduced three significant new tests:
- 1Llama 3.1 405B with 6-second TTFT requirements
- 2Llama 2 70B Interactive with stringent 450ms TTFT
- 3Relational Graph Attention Network
These benchmarks highlight the dramatic performance scaling in modern GPUs. Blackwell Ultra demonstrates up to 36x throughput improvements on large models compared to previous GPU generations. This is achieved through a combination of architectural improvements and software optimizations like TensorRT-LLM, which improved throughput for Llama models by 45% on Microsoft Azure deployments.
Memory efficiency innovations
Energy efficiency has become paramount in inference deployments, with Hopper platforms delivering 15x better efficiency than previous generations. This efficiency gain stems from innovations in both hardware architecture and memory management.
The key to these improvements is the evolution of memory subsystems in modern GPUs. HBM4 technology not only increases raw bandwidth but also improves power efficiency per operation. These memory innovations allow larger batch sizes to be processed while maintaining performance, enabling more concurrent inference requests to be handled by a single device.
The future of inference architectures
As LLM workloads continue to grow exponentially, GPU architectures are evolving to specifically address inference use cases rather than just training. Future architectures will likely feature more dedicated hardware for specific inference operations, further specialized tensor cores, and even more efficient memory hierarchies.
Emerging Architectural Trends:
- Dedicated hardware for specific inference operations
- Further specialized tensor cores for transformer operations
- More efficient memory hierarchies optimized for KV cache
- Architectural divergence between training and inference capabilities
- Hardware specialization for on-premises deployments
The trend toward hardware specialization will continue, with architectures increasingly differentiating between inference and training capabilities. This architectural divergence enables more targeted optimizations for specific workloads, particularly for on-premises deployments where enterprises want to own their inference infrastructure rather than rely exclusively on cloud services.
These architectural advancements provide the foundation for implementing advanced quantization techniques, which we'll explore next as a critical strategy for improving inference efficiency.
Quantization techniques and precision tradeoffs
Quantization is a critical technique for reducing the memory footprint and computational requirements of large language models during inference. By converting model weights from higher-precision formats like FP16 to lower-precision alternatives such as FP4 and INT8, organizations can dramatically improve inference efficiency with minimal impact on model quality.
Memory efficiency vs computational speed
FP4 presents a dual challenge in LLM deployment. While it enables substantial memory reduction compared to FP16, this comes with computational overhead. The Quantization (Quant) and Dequantization (Dequant) operations needed for lower-precision formats can slow down inference compared to higher-precision alternatives. Finding the right balance between memory savings and speed is essential.
Quantization impact on model performance
When implemented effectively, quantization techniques can reduce model size by up to 4x with less than 1% accuracy loss. This makes on-premises solutions more feasible for organizations with limited hardware resources. Post-training quantization approaches allow teams to compress existing models without requiring expensive retraining.
Hybrid quantization strategies
Various approaches combine different precision levels for optimal results:
Common Hybrid Strategies:
- Weight-only quantization targeting 4-bit precision
- INT8 KV cache for memory-efficient key-value storage
- Hybrid schemes using higher precision for sensitive layers
- Per-channel quantization to preserve important features
Implementation considerations
TensorRT-LLM provides robust support for implementing FP4 quantization, though efficiency varies by hardware generation. Newer GPUs (Ampere and beyond) offer native support for 4-bit operations, delivering significant throughput improvements. For older hardware, the quantization benefits may be less pronounced.
Implementation Factors to Consider:
- 1Hardware generation and native precision support
- 2Task sensitivity to precision loss
- 3Memory constraints of deployment environment
- 4Throughput vs. accuracy requirements
- 5Available software framework support
The selection of quantization techniques should be tailored to your specific hardware and performance requirements. Some tasks are more sensitive to precision loss than others, making the quantization approach a context-dependent decision.
Measurement and benchmarking
When evaluating quantized models, comprehensive benchmarking is crucial. Key metrics include perplexity (to measure language quality), memory consumption, and token generation speed. Different quantization methods show varying performance across these dimensions, with approaches like OmniQuant and GPTQ demonstrating strong results for FP4 implementations.
Essential Benchmarking Metrics:
- Perplexity (language quality)
- Memory consumption
- Token generation speed
- Task-specific accuracy
- Latency under various batch sizes
Organizations should establish clear performance thresholds and test quantized models against domain-specific tasks before deployment to ensure quality standards are maintained alongside efficiency gains.
With quantization strategies established, we can now turn our attention to the frameworks and batching techniques that tie all these optimizations together into production-ready inference systems.
Optimizing inference: frameworks, batching, and cost analysis
To bring together all the concepts we've explored, let's examine the frameworks, batching strategies, and cost considerations that create efficient inference systems in practice.
Understanding inference optimization challenges
Memory bandwidth is a critical factor in LLM inference performance. While generating the first token is typically compute-bound, subsequent decoding is memory-bound. This makes Memory Bandwidth Utilization (MBU) a crucial metric for optimization efforts. For shared online services, continuous batching is essential, while offline batch inference workloads can achieve high throughput with simpler techniques.
Key frameworks for inference optimization
Three major frameworks dominate the LLM inference landscape:
Batching strategies and performance implications
Three primary batching approaches exist, each with distinct advantages:
- 1
Static batching
Simplest approach with fixed batch size throughout inference - 2
Dynamic batching
Adjusts batch size based on incoming requests - 3
Continuous batching
Also known as in-flight batching, processes requests at the iteration level
Continuous batching demonstrates the best performance for most online services, with benchmarks showing up to 8x throughput over naive batching. For a typical A10 GPU, throughput scaling with batch size shows impressive gains:
Advanced optimization techniques
Modern inference pipelines employ several techniques to maximize performance:
Key Optimization Techniques:
- KV cache quantization: Reduces memory usage with minimal accuracy loss
- Kernel fusion: Combines adjacent operators for better latency
- Operator fusion: Consolidates computational tasks to minimize overhead
- Speculative decoding: Efficiently generates multiple future tokens from a smaller model
Hardware acceleration and efficiency
NVIDIA's Blackwell Ultra Architecture represents the cutting edge, offering:
- 3.1x throughput improvement over previous architectures in MLPerf v5.0 benchmarks
- Twice the attention-layer acceleration
- 1.5x more AI compute FLOPS than predecessors
- Advanced support for FP4 and FP6 calculations
Cost modeling across deployment scenarios
Cost optimization requires understanding the trade-offs between different quantization approaches and hardware configurations:
Cost Optimization Factors:
- 1Reducing precision from FP16 to INT8/INT4 can significantly decrease hardware requirements and cost
- 2Blackwell Ultra can reduce cost per token by up to 32x compared to H100 when optimally configured
- 3Tensor parallelism allows efficient distribution of workloads, improving cost efficiency at scale
- 4Higher batch sizes dramatically improve cost efficiency for shared inference services
For shared inference services, high batch sizes are critical for cost efficiency, with benchmarks showing significant cost reductions when operating at optimal batch sizes.
Latency-throughput trade-offs
There is an inherent trade-off between latency and throughput. Increasing batch size improves throughput but can negatively impact latency. Finding the optimal balance depends on specific use cases:
Use Case Optimization:
- Real-time applications: Require low latency at the expense of throughput
- Offline batch processing: Can maximize throughput without latency concerns
- Server scenarios: Can balance both with continuous batching techniques
Understanding whether inference is compute-bound or memory-bound helps in selecting the right optimization strategy for different deployment scenarios.
By carefully implementing these optimization strategies, organizations can achieve the ideal balance between performance, cost, and quality for their specific inference requirements.
Conclusion
Understanding GPU architecture and memory management is fundamental to achieving optimal LLM inference performance. The distinct requirements of prefill versus decode phases highlight why memory bandwidth, not just compute capacity, often determines real-world performance. Specialized hardware like NVIDIA's Blackwell Ultra with HBM4 memory represents the cutting edge, but optimizations are possible across all hardware tiers.
Key Technical Approaches:
- KV cache optimization through techniques like PagedAttention
- Strategic quantization to balance precision and performance
- Continuous batching to maximize throughput in production environments
The right combination of these methods can yield multiple orders of magnitude improvement in cost-efficiency.
Recommendations for Teams:
- 1Product teams should prioritize inference optimization earlier in the development cycle
- 2AI engineers should evaluate frameworks against specific workload characteristics
- 3Leadership should focus on informed infrastructure investments
For leadership, understanding these concepts enables more informed infrastructure investments, with potential ROI improvements of 5-10× through proper hardware selection and optimization techniques.