
Foundations of Inference Scaling
The scaling law from 2020 and 2022 has led to the development of LLMs that can extract patterns and understand large datasets quite effectively. Scaling laws have also shown that the training loss reduces when more training compute is provided to large models. As a result, the LLMs have shown emerging behaviour on tasks that they were not trained on.
Based on our estimated compute-optimal frontier, we predict that for the compute budget used to train Gopher, an optimal model should be 4 times smaller, while being training on 4 times more tokens. … The energy cost of a large language model is amortized through its usage for inference an fine-tuning. The benefits of a more optimally trained smaller model, therefore, extend beyond the immediate benefits of its improved performance.

But till 2024, the AI labs focused more on scaling the training phase by adding more compute and parallelization. Although the models were becoming more intelligent, they were not able to perform quite well on downstream reasoning tasks and evaluations.

James Wang the Director of Product Marketing @CerebrasSystems tweeted the timeline of AI compute. It is no surprise that AI labs focused more on scaling the training phase. And for inference, mostly techniques like quantization were employed. Quantization reduces the memory consumption but often leads to a potential loss in the model’s performance, especially on reasoning tasks.
To improve the downstream performance of LLMs (on reasoning tasks), there has to be enough exploration space for the LLM to work and find better answers. When the exploration space itself is constrained, the LLM cannot find relevant answers, leading to suboptimal performance. Keeping this in mind, researcher started working on search-based techniques that the LLMs could use during inference to enhance their performance. This is known as inference search or test-time search.
Inference scaling, also known as test-time scaling or test-time compute, by definition, is a process of allocating GPUs (computational resources) during the model’s runtime or deployement to enhance its output performance. The purpose is to increase the accuracy and reasoning quality of the LLMs.
Inference = Test-time
Inference scaling refers to techniques that optimize LLM performance during deployment.
For instance, Monte Carlo Tree Search, best-of-n, and majority voting are some of the search-based techniques. But again this would require more GPU during inference which would again raise up the infrastructure cost and budget.
As such, you will see that the tasks themselves are divided into two categories:
- 1General tasks that require no reasoning, therefore fewer GPUs. This would resemble tasks such as text, summarization, translation, creative writing, etc. These tasks are straightforward and require little to no thinking.
- 2Reasoning tasks require extensive reasoning or thinking, and more GPUs. This would include tasks such as advanced mathematics or providing a PhD-level solution, multimodal reasoning, etc. These tasks require a lot of thinking before answering.

Inference cost vs Performance graph comparison of OpenAI o1 and o3 variants | Source: Introducing OpenAI o3 and o4-mini
In 2025, AI labs are following this paradigm of task-based LLM development, where they are developing models for general-purpose and reasoning tasks. OpenAI is providing GPT-4 and GPT-4.5 for general-purpose tasks, and O1, O3, and O4 for reasoning tasks. Similarly, Google is providing Gemini Flash for general-purpose tasks and Gemini Pro for reasoning tasks.
In this article, we will be focusing on inference scaling for reasoning models like the ‘o’ series from OpenAI and Gemini Pro from Google DeepMind. We will cover the fundamentals and learn how inference scaling offers better reasoning.
Why Inference Scaling Matters?
Inference scaling enables the model to allocate more compute resources to searching for the correct answer through intermediate reasoning steps or “thinking”. Models like the ‘o’ series from OpenAI spend more time thinking about the problem. During the thinking process, the model tends to come up with various reasons or intermediate steps for a given problem.
Because the model now produces n number of responses for a single problem, it requires more computational resources. The more reasoning samples the models produce, the better it is for the model to select the most frequent answer as the final response.
This is essentially the crux of inference scaling, also known as test-time scaling.
What is Reasoning or Thinking for Inference?
We have established that few (compute) resources are required for general inference tasks, such as text summarization and creative writing. This is because such tasks are semantically and syntactically anchored. In other words, the outputs are based on the extracted pattern and the ordered sequence of the tokens. They are an end-to-end process – input in and output out. There is no intermediate process.
Reasoning, on the other hand, incorporates an intermediate process or the thinking process. It is where the model spends time processing and splitting out reasoning steps before providing the output.
Think of it as spending time planning a trip or vacation. You cannot simply take a handful of money and go on a vacation; you need to plan where you will stay, the places you will visit, the food you will eat, a shopping budget, and so on. Similarly, if you are solving a mathematical problem, you need to work out intermediate steps to find the correct answer.

Illustration of answer without reasoning and with reasoning | Source: The State of LLM Reasoning Model Inference
In order for the model to reason properly, it needs three things:
- 1Reasoning training data to learn thinking or intermediate steps.
- 2Inference computing involves thinking or producing intermediate steps before answering.
- 3Reinforcement learning is used to identify the most suitable intermediate steps that lead to the final output.
In this article, we will only focus on steps 1 and 2.
Chain-of-thoughts as Reasoning Data
When it comes to reasoning with data, the most common approach is to leverage the Chain-of-thought prompting-like dataset.

Difference between standard prompting and CoT prompting | Source: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
The CoT comprises three data points (input, steps, output) instead of two (input and output). When CoT-based data is provided to the LLM, the LLM tends to develop reasoning properties. And as the model scales in size according to the scaling laws the model becomes more and more accurate in solving difficult reasoning problems.
To get an idea of what the CoT dataset looks like, check out NuminaMath-CoT in Huggingface here.

Model performance via CoT improves as model scales up | Source: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Training the LLM on the CoT prompting dataset enables the model to develop CoT reasoning capabilities, which is helpful in inference.
Key Dimensions and Performance Trade-offs
Inference scaling techniques affect performance across multiple dimensions:
- Compute: Total computational resources required for inference
- Latency: Time to generate the first token of a response
- Throughput: Number of tokens processed per second
- Cost: Financial expense of running inference
- Response Length: Maximum output tokens the model can generate
- Memory: RAM requirements for model weights and intermediate states
Each technique involves inherent trade-offs across these dimensions. For instance, quantization may reduce memory usage but potentially impact output quality.
Training Scale versus Inference Scale
Understanding the distinction between training and inference phases helps optimize LLM deployment strategies. These phases have fundamentally different characteristics and requirements.
Training optimization and inference optimization require different approaches. While training focuses on convergence, inference prioritizes resource efficiency.
Test-time Scaling Methods
Let’s assume that the model has been trained and it is able to produce CoT, reasoning, or intermediate steps before providing the final answer. Now, the key thing to understand is that the model needs to produce various CoTs along with the final answer. This can be done using various approaches.
… OpenAI o1, a new large language model trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers—it can produce a long internal chain of thought before responding to the user.

OpenAI demonstrated that o1 performance improved when provided more compute in both training and testing time | Source: Learning to reason with LLMs.
The most prominent models, such as the ‘o’ series from OpenAI, use scaled reinforcement learning to train their reasoning models. But there are other methods as well like Tree-of-thought, Best-of-N, Beam search, etc. Let’s discuss some of these methods briefly.
Tree-of-Thought
Tree-of-Thought (ToT) extends Chain-of-Thought by exploring multiple reasoning paths simultaneously. This approach creates a branching structure of potential solutions.

Difference between IO, CoT, and ToT prompting methods | Source: Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning
Two primary search strategies exist for traversing the reasoning tree:
- Depth-First Search (DFS): Explores a single reasoning path completely before backtracking
- Breadth-First Search (BFS): Evaluates all possible next steps before proceeding deeper
DFS excels when:
- 1The solution space has clear indicators of progress
- 2Early detection of dead ends is possible
- 3Memory constraints limit tracking multiple paths
BFS performs better when:
- 1Multiple viable solution paths exist
- 2The problem has misleading intermediate states
- 3Computational resources allow parallel evaluation
ToT implementations have demonstrated significant improvements on complex reasoning tasks like mathematical problem-solving and logical puzzles.
Self-Consistency & Ensemble Voting
Self-consistency enhances reasoning by generating multiple independent solutions and selecting the most consistent answer. This approach compensates for the stochastic nature of language model outputs.
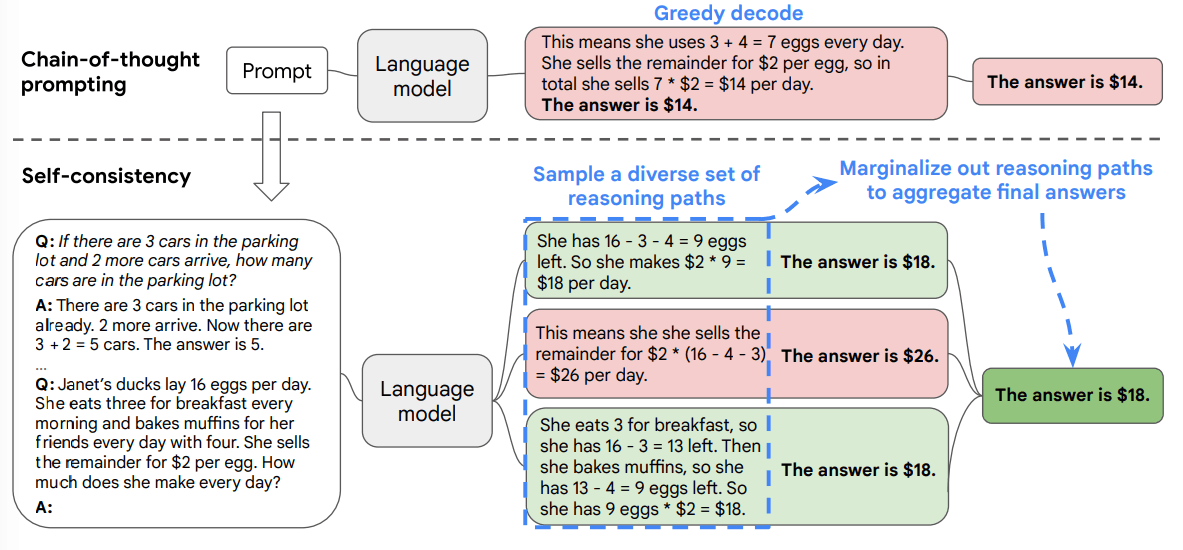
Overview of the self-consistency method. | Source: Self-Consistency Improves Chain of Thought Reasoning in Language Models
The process works as follows:
- 1Generate N different reasoning chains for the same problem
- 2Extract the final answer from each chain
- 3Select the most frequent answer as the final response
For challenging problems, a weighted voting mechanism can improve results:
Where I is an indicator function that equals 1 when the condition is true.
Self-consistency methods have shown up to 30% improvement on complex reasoning benchmarks compared to single-pass approaches.
Journey Learning

Overview of Journey Learning | Source: O1 Replication Journey: A Strategic Progress Report – Part 1
Journey Learning is a groundbreaking approach that moves beyond traditional "shortcut learning." Instead of focusing only on correct answers, this method embraces the entire problem-solving process—including mistakes, reflections, and corrections.
The key differences between shortcut and journey learning include:
In practice, journey learning encourages models to:
- Explore multiple solution paths
- Learn from mistakes
- Reflect on reasoning steps
- Make corrections when necessary
One striking example shows how journey learning improved performance on math problems by 8.4% using just 327 training examples. This approach mimics human-like thinking, where we rarely solve complex problems in a single, perfect attempt.
Monte Carlo Tree Search

Overview of Speculative Contrastive MCTS | Source: Interpretable Contrastive Monte Carlo Tree Search Reasoning
Monte Carlo Tree Search (MCTS) is a powerful decision-making algorithm that helps language models improve their reasoning abilities. It works through four key phases:
- 1
Node Selection
The algorithm starts at the root and selects promising nodes to explore using strategies like Upper Confidence Bound on Trees (UCT). - 2
Expansion
New child nodes are added to represent possible next steps in reasoning. - 3
Simulation
The algorithm plays out potential solutions from the selected node. - 4
Backpropagation
Results from simulations are used to update the value of previously visited nodes.
MCTS helps models balance:
- Exploring new possibilities
- Exploiting known good paths
Recent innovations like SC-MCTS* enhance this approach by adding:
- Contrastive reward models to better evaluate node quality
- Speculative decoding to speed up reasoning by 52%
- Refined backpropagation that favors steady progress
This structured exploration approach has enabled smaller models to outperform larger ones on complex reasoning tasks, including surpassing OpenAI's o1-mini by 17.4% on multi-step planning problems.
Scaling up Test-Time Compute with Latent Reasoning
The recurrent depth approach introduces a novel architecture that enables language models to scale computational resources during test time by reasoning in latent space. At its core, the architecture consists of three functional blocks:
- A prelude block that embeds input tokens into latent space
- A recurrent core block that iteratively processes these embeddings
- A coda block that decodes the final state back into output tokens
The key innovation is the ability to run the recurrent block multiple times at test time. This allows the model to:
- Dedicate more computational resources to difficult problems
- Process information in high-dimensional latent space before generating tokens
- Capture types of reasoning that are challenging to represent in words
During training, the model learns with randomly varying recurrence counts, preparing it to handle different computational depths at inference time. When tested, performance on reasoning tasks improves significantly with increased recurrence, demonstrating that the model effectively utilizes additional compute to refine its thinking.
This approach avoids limitations of traditional chain-of-thought methods by eliminating the need for specialized training data or long context windows.
Chain-of-Associated-Thoughts
Chain-of-Associated-Thoughts (CoAT) represents an innovative framework designed to enhance large language model reasoning by incorporating human-like associative thinking. This approach addresses limitations of both "fast thinking" inference and standard chain-of-thought methods.
The CoAT framework combines two powerful mechanisms:
- 1Associative Memory: Enables the model to dynamically incorporate new information during reasoning, similar to how humans form connections between related concepts.
- 2Optimized Monte Carlo Tree Search (MCTS): Structures the exploration of reasoning pathways, ensuring efficient routing through the knowledge space.
During processing, CoAT follows this workflow:
- The model receives an initial query
- At each reasoning step, it generates associative memories related to the current state
- These associations expand the search space with relevant knowledge
- MCTS guides path selection to find optimal reasoning trajectories
Unlike conventional approaches that rely solely on initial information, CoAT continuously supplements and refines its knowledge base. This allows the model to:
- Revisit earlier inferences with new context
- Incorporate evolving information during reasoning
- Generate more accurate and comprehensive outputs
Experimental results show CoAT significantly outperforms traditional inference methods in accuracy, coherence, and diversity across various reasoning tasks.
s1: Simple test-time scaling
s1 presents a straightforward approach to improve language model reasoning with minimal resources. Unlike complex methods using millions of examples, s1 achieves impressive results through:
- 1Training on just 1,000 carefully selected examples (s1K dataset)
- 2Quick supervised fine-tuning (26 minutes on 16 H100 GPUs)
- 3"Budget forcing" to control thinking time
Budget forcing is key - it can limit thinking by forcefully ending the process after a set token count, or extend thinking by preventing stops and appending "Wait" prompts.

Importance of “wait” token in s1 inference scaling. | Source: s1: Simple test-time scaling
The results are remarkable - s1-32B shows clear test-time scaling behavior across benchmarks like MATH500 (93% accuracy), while being significantly more sample-efficient than competitors. This demonstrates that models already possess reasoning capabilities from pretraining, with fine-tuning merely activating these abilities.
Benchmarking
Now, let’s see the benchmarking of some of the reasoning models in 2025.
In test-time scaling, models with extended reasoning capabilities show clear performance advantages. Claude 3.7 Sonnet with Extended Thinking demonstrates impressive results on specialized reasoning tasks (GPQA Diamond: 84.8%, MATH-500: 96.2%) while maintaining strong MMMU performance. The OpenAI o-series models excel across benchmarks, with o3 and o4-mini achieving near-perfect scores on GSM8K and leading MMMU performance. DeepSeek R1, while lacking multimodal support, shows outstanding performance on math-focused tests (MATH-500: 97.3%), highlighting how test-time scaling particularly benefits complex reasoning tasks that require multi-step thinking.
Conclusion
Inference scaling represents a significant advancement in how AI models reason through complex problems. Let's review the core concepts and highlights from our exploration.
Essential Definitions
Inference Scaling: The allocation of computing resources during model runtime to enhance output quality.
Test-time Compute: Another term for inference scaling, focusing on computational resources used during deployment.
Chain-of-Thought: A reasoning approach where models produce intermediate steps before arriving at final answers.
Critical Methods for Enhanced Reasoning
Several techniques have emerged to improve model reasoning capabilities:
- 1Tree-of-Thought: Creates branching structures of potential solutions using either:
- 2Self-Consistency: Generates multiple independent solutions and selects the most frequent answer.
Performance Impact
The benchmarking results demonstrate clear benefits:
- OpenAI's o3 achieved 96.9% on GSM1k
- Models with extended reasoning show remarkable improvements on specialized tasks
- DeepSeek R1 reached 97.3% on MATH-500 benchmarks
Why This Matters
Inference scaling transforms how models approach reasoning tasks. By dedicating computational resources to "thinking" through problems step-by-step, models can:
- Generate multiple reasoning paths
- Evaluate different solution strategies
- Select the most consistent answers
This mirrors human problem-solving more closely than traditional approaches. Rather than simply pattern-matching or providing direct answers, these models work through problems methodically.
The future of AI reasoning depends on balancing computational resources with effective reasoning strategies. As inference scaling techniques continue to evolve, we can expect even more impressive results on complex reasoning tasks.